说话人识别综述
引言
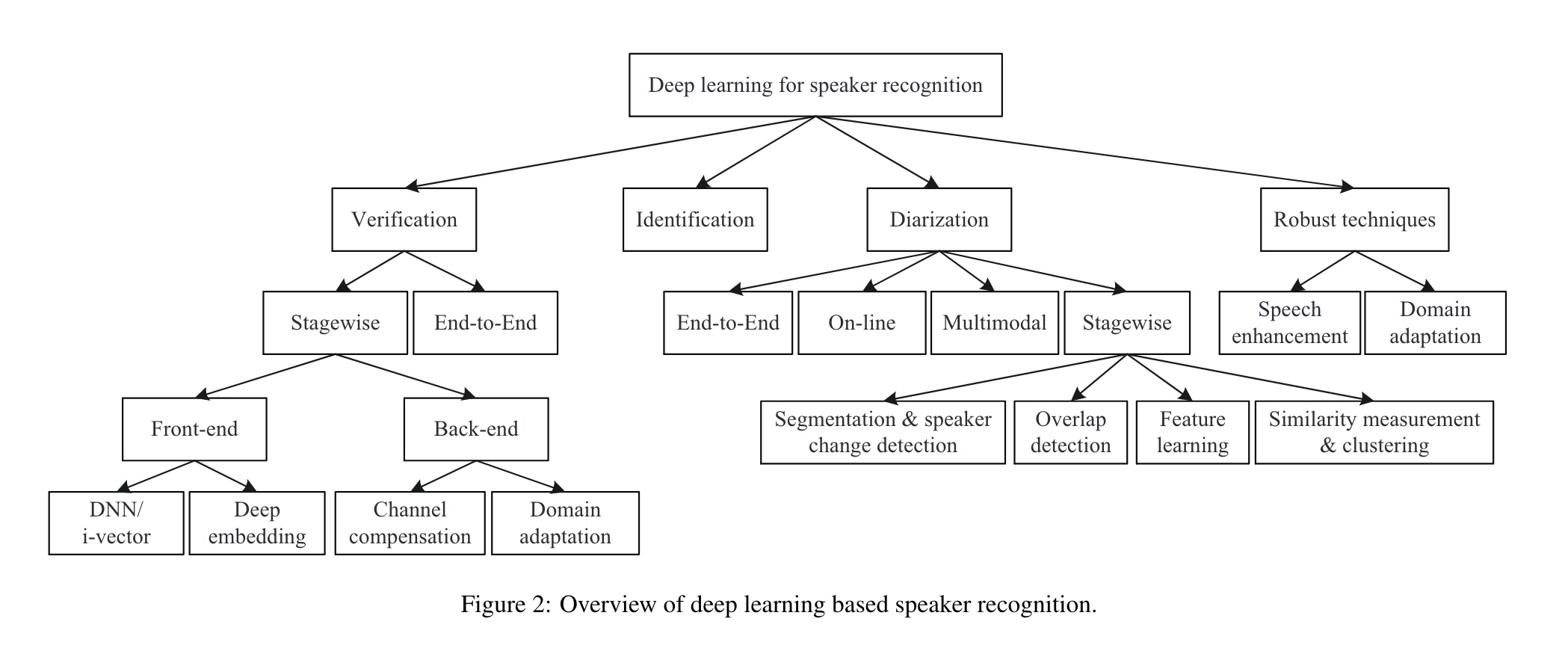
说话人识别(speaker recognization)主要的子任务
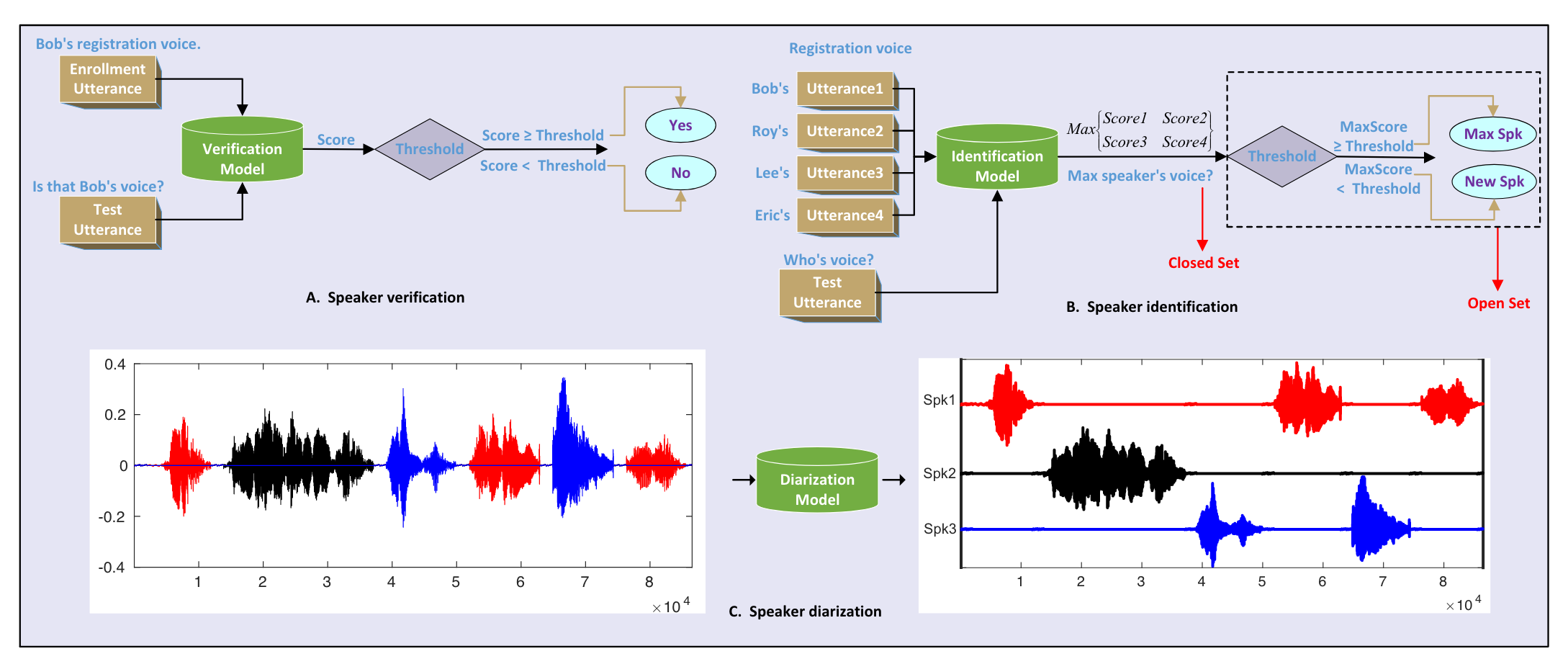
- speaker verification:基于一个说话人的录音,验证输入语音是否属于该说话人,即1对1的比对。
- speaker identification:从多个说话人库中,检索输入语音属于哪个说话人,即1对多的比对。
- speaker diarization:将一段对话音频根据说话人分割成多段音频,每段属于同一个说话人。
- robust speaker recognition
Speaker Verification
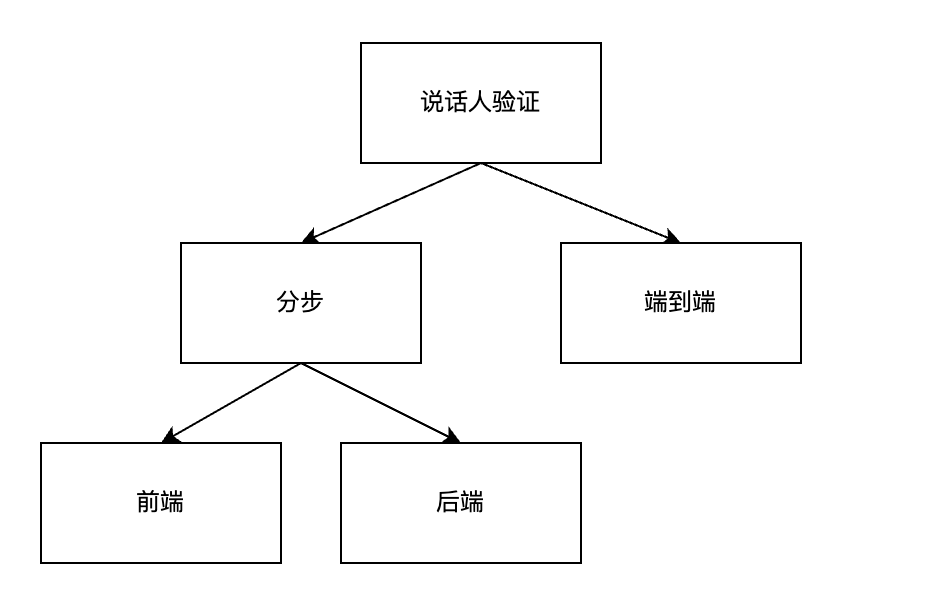
说话人验证有两种范式:分步式和端到端。
分步式一般包括特征提取和相似度计算两个步骤。
端到端方法输入一组语音对,直接输出该语音对的相似度得分。
两种范式最大的差异在损失函数。
经典方法
GMM-UBM
Universal Background Model (UBM)是一个大型 GMM(如512到2048 个混合),经过训练来表示与说话者无关的特征分布。
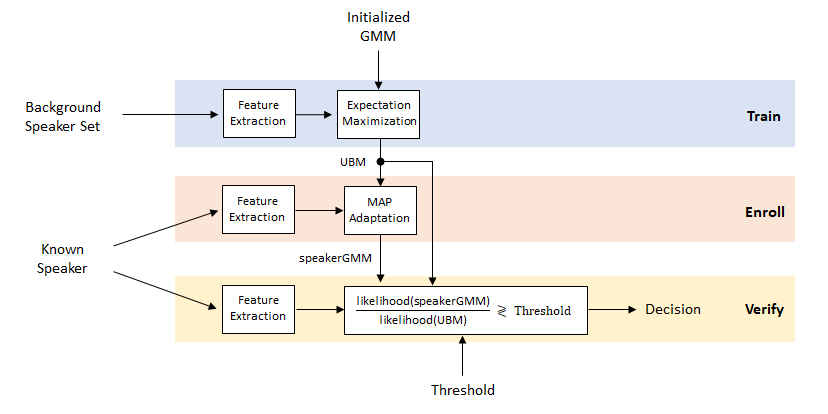
在说话人验证系统中,UBM 是一种与说话人无关的高斯混合模型 (GMM),使用来自大量说话人的语音样本进行训练,以表示一般语音特征。使用来自特定注册说话人的语音样本训练,得到表示特定说话人特征的GMM。对于一条未知样本,可以计算特定说话人模型和 UBM 的匹配分数之间的似然比(Likelihood Ratio),从而判断样本的说话人。 此外UBM还可以充当特定说话人GMM训练时最大后验概率 (MAP) 参数估计中的先验模型。
Train
UBM使用全部说话人样本,训练一个说话人无关的通用GMM。
对于特征向量$x$,高斯混合密度可以这样表示:
\[P(x \mid \lambda) = \sum_{k=1}^M w_k \times g(x \mid \mu_k, \Sigma_k)\]即多个高斯密度的加权和。
GMM的参数由训练样本的特征通过EM算法得到。对于样本序列,$X = (x_1, x_2, …, x_T)$,要求整个序列的似然概率最大,假设每个样本是独立的,则样本序列的似然概率:
\[\log p(X \mid \lambda) = \frac{1}{T} \sum_t \log p(x_t \mid \lambda)\]Enroll
使用一个说话人的样本特征,给每个说话人训练一个说话人相关的GMM,即这些说话人被“注册”了。
有两种方式:
- 用说话人的样本(注册样本),重新训一个相对较小的GMM;
- 用UBM作为初始化,使用MAP方法微调一个说话人相关的GMM;
Verify
对于一条待测样本,先计算各注册说话人模型的似然概率,然后减去UBM的似然概率,得到每个注册说话人的的LR。通过阈值来判断是否接受。
GMM-UBM/i-vector
GMM-UBM方法容易受到说话人发音变化和信道变化的干扰。
说话人/会话可变性:因信道不同、音素不同和说话人身体变化等,同一个说话人的不同录音会有变化。
能否找到说话人可变性和信道可变性无关的表征?
i-vector:identity vector/intermediate vector
i-vector方法消除了说话人可变性和信道可变性子空间之间的区别,并在公共约束低维空间(称为“总可变性空间”)中对两者进行建模,将高维度的输入序列映射成低维度的固定长度特征向量。
supervector:将GMM的均值向量堆在一起,组成一个特征向量。
因子分析模型:
\[M = m + Tw\]M表示说话人和信道相关的supervector;
m是一个说话人和信道均无关的supervector,比如UBM的supervector;
矩阵T由训练样本得到;
w是一个符合标准的正态分布的隐变量,由给定的utterance通过MAP确定。给定一条语音片段,利用GMM-UBM可以收集对应的统计量,然后计算隐变量。
\[w = (I + T^tΣ^{−1}N (u)T )^{−1}.T^tΣ^{−1} \tilde{F} (u).\]ivector就是w分布的均值作为特征。
将因子分析作为特征提取器,从utterance提取特征ivector,验证时可以直接比较一对特征的相似度,比如余弦相似度。

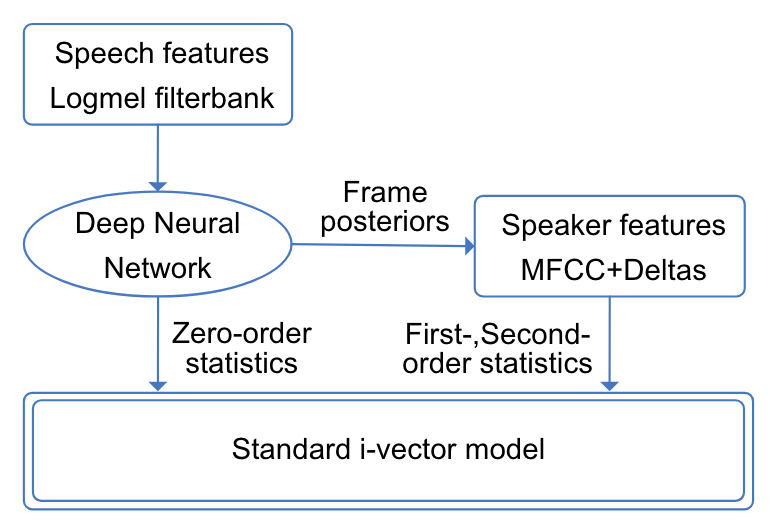
DNN-UBM/i-vector
计算i-vector所需要的统计量,都是从语音帧的后验概率收集得到的。
理论上,可以使用其他模型来替代GMM-UBM产生后验。
DNN-UBM/i-vector框架利用ASR的DNN声学模型替代GMM-UBM。
类似的,TDNN、LSTM均可用于替代GMM-UBM,并带来性能提升。
计算复杂度和标注数据需求量较高。
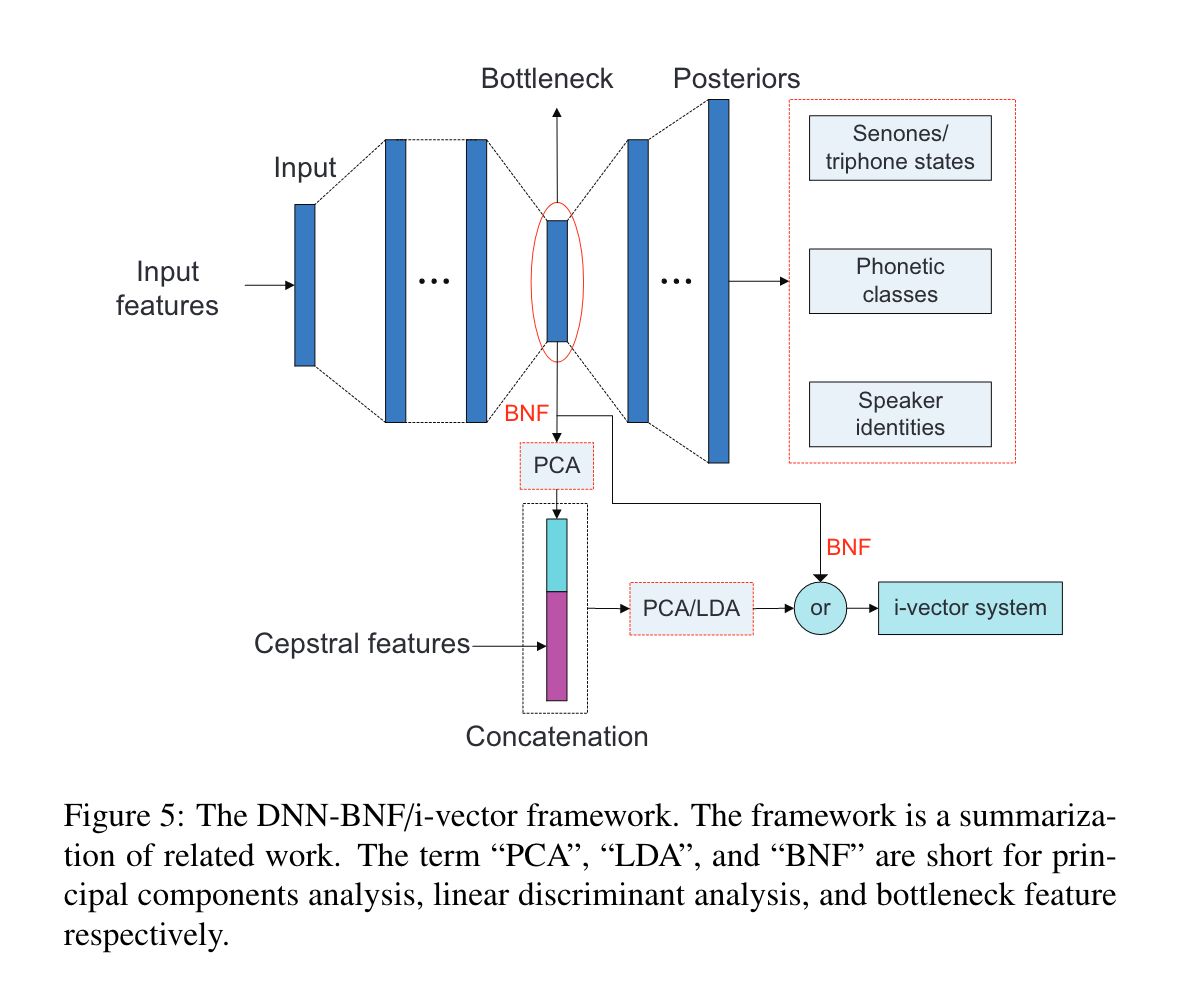
DNN-BNF/i-vector
提取DNN的bottleneck特征,用于因子分析,生成i-vector。
DNN可以是ASR的音素分类模型,也可以是说话人分类模型。
DNN-BNF方法是在特征层面的改动,比MFCC特征效果更好。
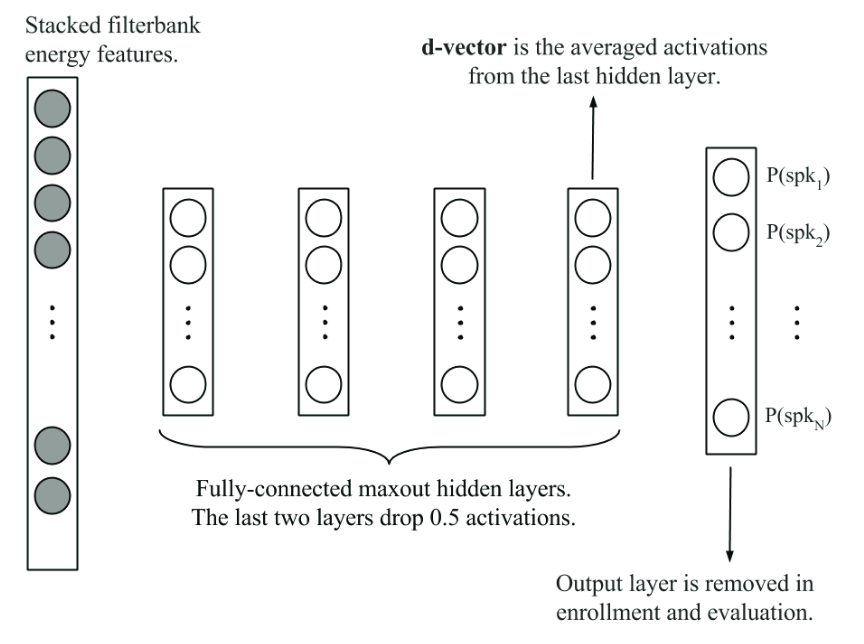
Deep embedding方法
Deep embedding是使用DNN将说话人嵌入到一个向量空间。
两个典型的深度embedding:
- d-vector:帧级别隐层变量的平均值,神经网络用于帧级别的说话人分类;
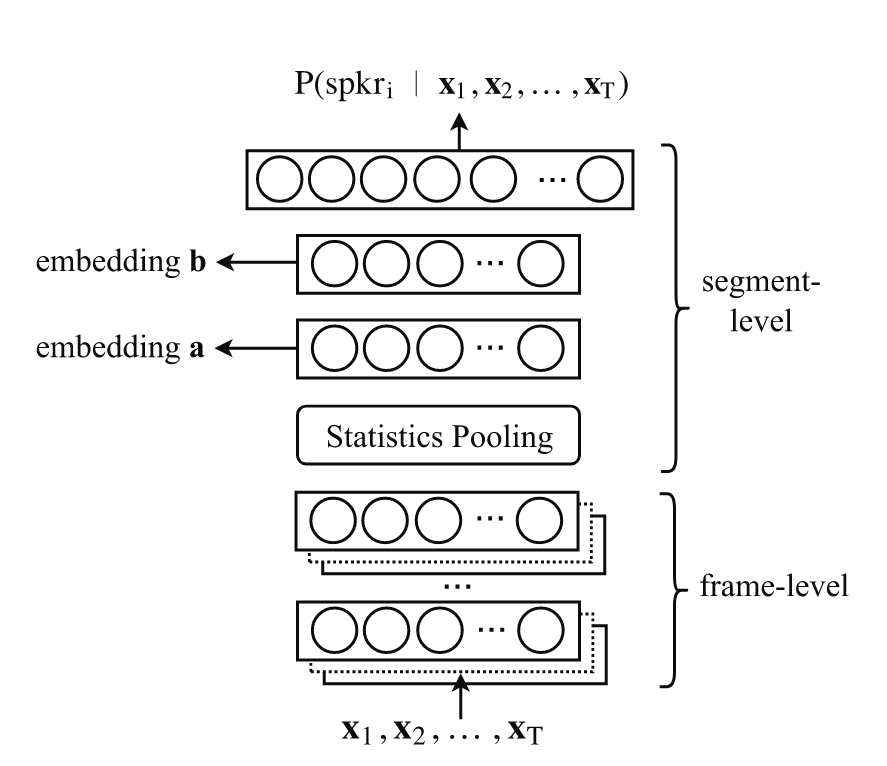
- x-vector:句子级别的隐层变量,神经网络用于句子级别的说话人分类,架构包括三部分:
- 帧级别特征提取层;
- 统计层,将帧级别特征的均值和方差拼接,构成新的特征;
- 分类层,前馈神经网络,x-vector可以来自于该部分的任意一层;
Deep embedding系统有四个关键部分:
- 网络输入;
- 网络结构;
- 时间池化;
- 目标函数;
网络结构和输入
TDNN:沿时间轴的一维卷积作为特征提取器。被x-vector架构采用。
ResNet:沿时间和频率维度的2D卷积。
raw wave NN:以时域信号直接作为输入,如CNN,Wav2Spk。
RNN经常用于文本相关的说话人验证。
CNN+RNN混合架构能增强性能。
目前卷积类网络和Fbank/MFCC特征居多。
时间池化层
时间池化层是帧级别隐层和句子级别隐层间的桥梁。
- 平均池化
平均池化最常用:
\[\mathbf{u} = \frac{1}{T}\sum_{t=1}^{T}\mathbf{h}_t\]- 统计池化
计算特征向量的均值和标准差,拼接成新向量。
\[\mathbf{u}=[\mathbf{m}^T,\mathbf{d}^T]^T\]- 基于self-attention的池化
无论是平均池化还是统计池化,均假设所有帧贡献相当。
self-attention池化相当于加权平均,按照QKV机制,这里的Q是frame-level层的最后一层的输出H,K是权重向量,V也是H。
首先计算权重:
\[\mathbf{a}^{(k)} = softmax(\mathbf{w_{s2}}^{(k)}tanh(W_{s1}^{(k)}H^T)), k=1,2,...,K\]重点是$\mathbf{w_{s2}}$向量用点积来计算每一帧的权重,是一个可学习的参数。k表示可以有多个头,学习不同空间的权重。
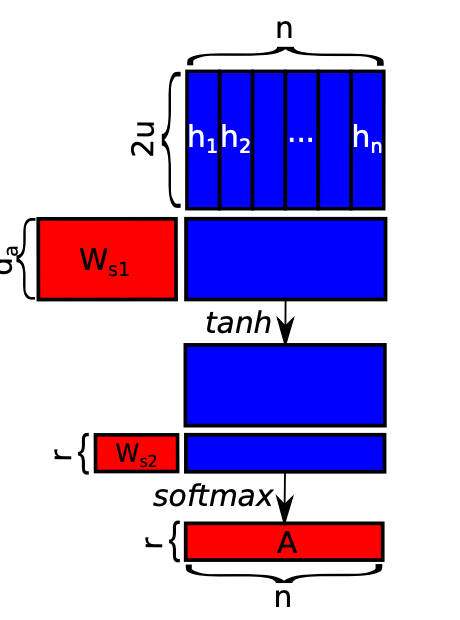
权重学习到后,可以求的加权平均值和对应标准差:
\[\mathbf{\widetilde{m}}^{(k)}=\sum^T_{t=1}\alpha^{(k)}_t\mathbf{h}_t\] \[\mathbf{\widetilde{d}}^{(k)}=\sqrt{\sum^T_{t=1}\alpha_t(\mathbf{h}_t-\mathbf{\widetilde{m}}^{(k)})^2}\]在注意力框架下,时间池化层有多种具体的实现,最简单的方法是直接利用多头的加权平均值:
\[\mathbf{u}=[\mathbf{\widetilde{m}}^{(1)^T},\mathbf{\widetilde{m}}^{(2)^T},...,\mathbf{\widetilde{m}}^{(K)^T}]^T\]- NetVLAD池化
Vector of Locally Aggregated Descriptors,局部聚合描述符向量。
NetVLAD是基于VLAD开发的带可训练参数的池化层,可以理解成可训练的聚类。
隐层变量$W\times H\times D$、隐变量展开$N\times D$、聚类M个类,算中心点残差N*M个,每个类N个残差聚合成1个,最后固定维度$M\times D$.
- LDE池化
learnable dictionary encoding (LDE)
- patial pyramid pooling
全局平均池化可以实现变长输入投影到固定维度,但是会丢失空间信息。
spatial pyramid pooling其实就是将输入分割成固定数量的块,每块内部进行平均池化得到固定大小的向量,各块向量拼接形成新向量。分割数量按照锥形设置多组,最少为一,相当于全局池化。多组向量拼接形成池化后的特征。
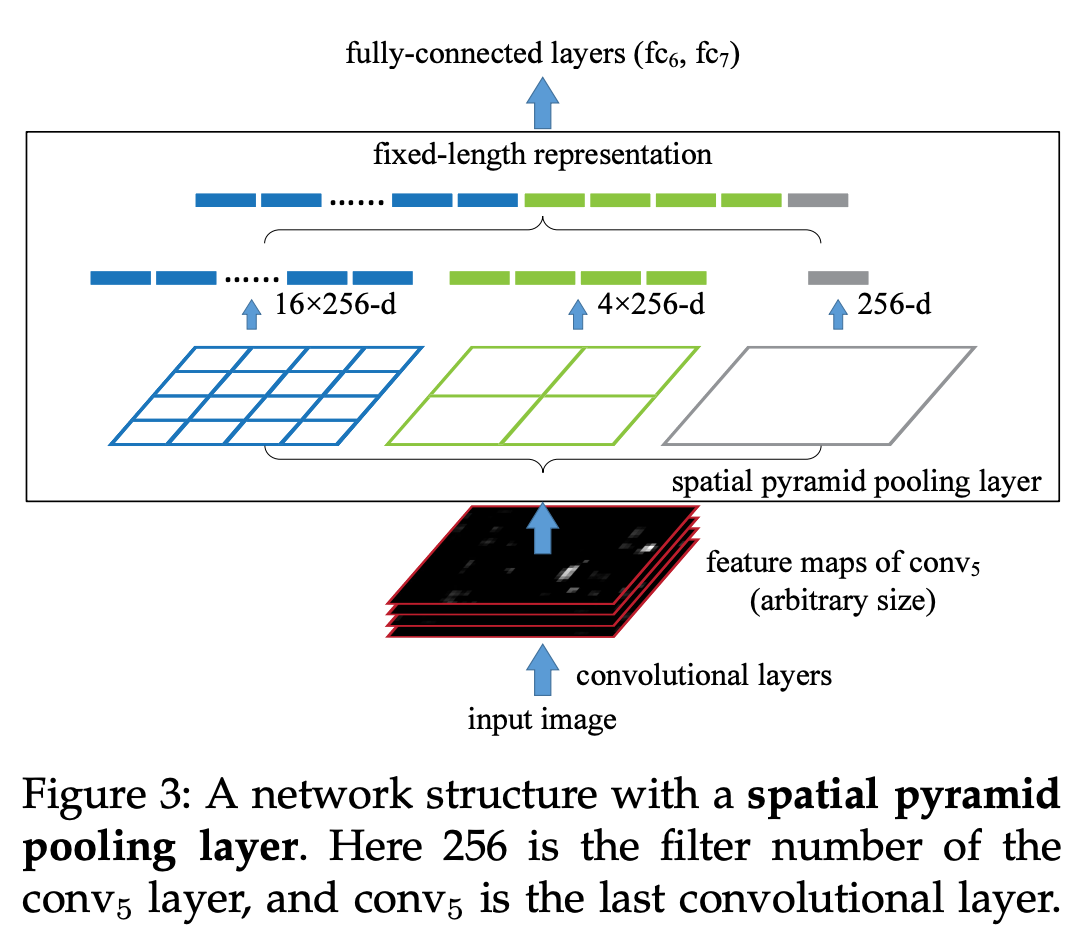
目标函数
通常采用基于分类的目标函数。
但是说话人验证是一个开集任务,取的是deep embedding,所以看重的是特征区分性,而不是最终的分类准确率。
- softmax的变体
softmax函数促进不同类间的差异最大化,但对于类内的差异没有显式约束,使其最小化。典型的有:
-
Angular softmax (ASoftmax) loss
-
Additive margin softmax (AMSoftmax) loss
-
Additive angular margin softmax (AAMSoftmax) loss
相比于基础softmax,以上几种变体让学习到的特征符合角度分布,这与后端的余弦相似度打分相匹配。此外引入的余弦余量通过定量地控制类间的决策边界从而最小化类内方差。
- softmax的正则化
通过给softmax增加正则化项,来提升分类区分性。
\[\mathcal{L} = \mathcal{L}_S+\lambda\mathcal{L}_{Regular}\]典型的包括:
- Center loss
每个batch,embedding向量和所属类的中心点向量欧氏距离作为正则项,类的中心点向量训练时会更新。
\[\mathcal{L}_C=\frac{1}{2}\sum^N_{n=1}||\mathbf{e}_n-\mathbf{c}_{l_n}||^2\]- Ring loss
将embedding向量的L1范数限制在某个目标值R。
-
Minimum hyperspherical energy criterion
-
Gaussian prior
-
Triplet loss
- 多任务学习
尽管直观上文本内容可能对文本无关的说话人识别有害,但很多实验证明引入文本的音素信息对说话人识别有帮助。
端到端方法
输入一对语音段,模型输出相似度得分。
和deep embedding方法的主要差异在于损失函数。
端到端说话人验证的损失函数设计要考虑三个问题:
- 如何让神经网络朝目标方向优化;
- 如何定义相似度度量方式;
- 如何选择并构建训练样本对;
相比于非端到端方法多使用基于分类的损失函数,端到端方法使用的是直接基于验证的损失函数,有两大基本好处:
- 说话人验证是面向开集的学习,基于验证的损失函数和测试保持一致,可以直接输出验证分数;
- 基于验证的损失函数,使输出层不会随着训练集说话人数量增加而变得巨大。
端到端系统最大的缺点是难以训练,包括样本对生成和模型难收敛。常用的可以有以下几类:
- Pairwise loss
用一对样本对计算损失函数。典型包括:
- Binary cross-entropy loss
最常用的是binary cross-entropy loss(BCE)。
\[\mathcal{L}_{BCE}=-\sum^N_{n=1}[l_n\ln(p(\mathbf{x}^e_n,\mathbf{x}^t_n))+\eta(1-l_n)\ln(1-p(\mathbf{x}^e_n,\mathbf{x}^t_n))]\]$x^e_n$和$x^t_n$分别是待验证的两条说话人特征,$l_n$是这一对特征的是否同一人的真实标签。
这是一个标准的BCE loss,引入$\eta$是为了平衡不属于同一人的样本对占全体的比重。
$p(\mathbf{x}^e_n,\mathbf{x}^t_n)$是一对样本输入同一人的概率,可以理解为相似度,不同BCE loss的变体正是对概率计算的改动。
有用余弦相似度+sigmoid函数的方法。
有基于PLDA的相似度计算方法。
还有直接利用神经网络计算相似度得分的方法。
- Contrastive loss
对比学习的损失函数是另一个常用方法。
\[\mathcal{L}_C=\frac{1}{2N}\sum_{n=1}^N(l_nd^2_n+(1-ln)\max(\rho-d_n,0)^2)\]$d_n$表示两个embedding样本对间的欧氏距离,$\rho$是手动定义的余量,平衡$d_n$上界。
可以看到最小化该损失函数,就是让同类距离变小,不同类距离变大。
对比学习损失函数过于难训练,可以使用softmax预训练,Contrastive微调。
-
Discriminant analysis loss
-
false alarm rate and miss detection rate
直接最小化$P_{fa}$和$P_{miss}$的加权和,作为目标函数。为了可导,使用sigmoid替代统计指标的指示函数。
- Triplet loss
由三条语料构成一个训练输入,其中两条来自同一个说话人,分别充当锚点语料和正语料,第三条来自不同说话人,充当负语料。
triplet loss旨在于使锚点语料和正语料相似度更高,让锚点语料和负语料相似度下降。即旨在于:
\[s^{an}_n-s^{ap}_n+\zeta)\le0\]其中$s_n^{a*}$是两个语料间的相似度,一般是余弦相似度和欧氏距离。
所以triplet loss的形态:
\[\mathcal{L}_{trip}=\sum^N_{n=1}\max(0,s^{an}_n-s^{ap}_n+\zeta)\]注意只有$\max(0,s^{an}_n-s^{ap}_n+\zeta) \gt 0$才对梯度有贡献。
要选择有效的三样本,可以使用“hard negative”方法采样,分为两步:
- 随机采样同一个说话人的两个样本,用作锚点和正样本;
- 对每个锚点,从剩下的说话人样本中,随机选择一个满足$\max(0,s^{an}_n-s^{ap}_n+\zeta) \gt 0$的负样本。
- Quadruplet loss
四条语料构成一个训练输入,其中两条来自同一个说话人$\mathcal{X}{same}$,另外两条来自另一个说话人$\mathcal{X}{diff}$。
四元损失函数可以看作最大化ROC曲线下某个指定区间的面积,即最大化pAUC。
- Prototypical network loss
最初是用于few-shot learning的。
Speaker Identification
说话人鉴别是说话人验证的泛化表示,多个说话人和特定单一说话人的区别。
它们涉及的基础技术一致。
Speaker Diarization
说话人分离也有分步方法和端到端方法。
分步方法和说话人验证有联系和区别。
相同点:共享如VAD、说话人特征提取等模块;
不同点:
- 说话人数量不同,SI假设一条语音就一个说话人,SD假设说话人数量未知;
- SI需要注册,和注册音频比较,SD不需要注册;
- SI说话人就一个不存在重叠问题,SD存在多人重叠说话问题;
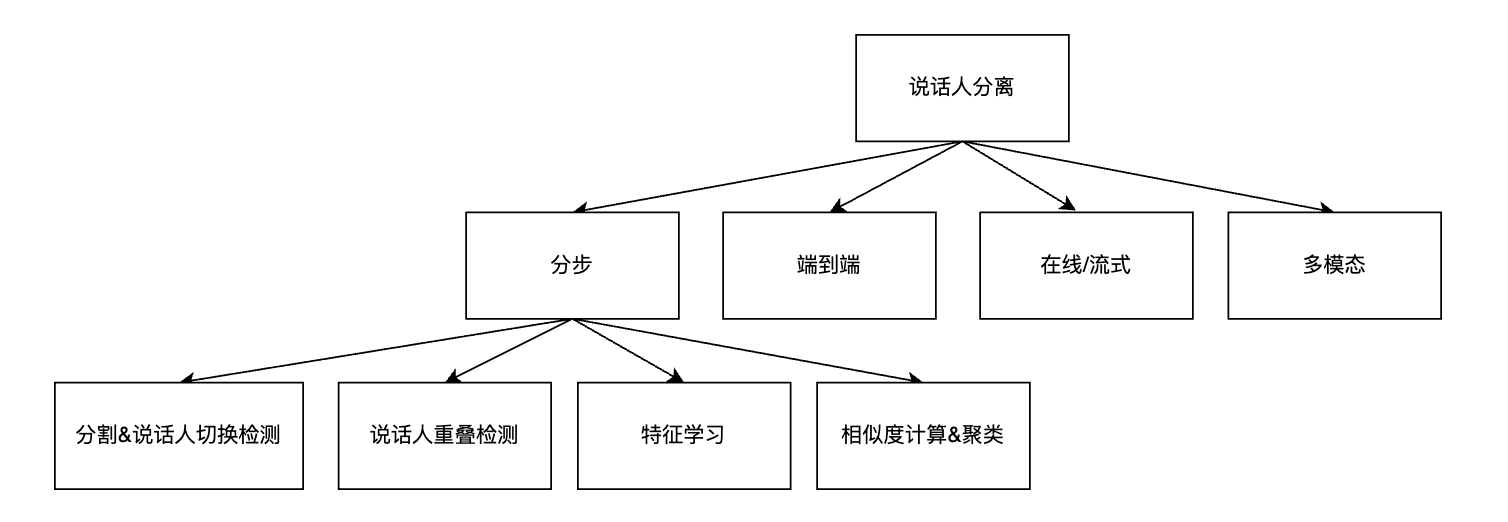
分步骤方法
多个模块配合,一步步完成整个SD过程。

大部分分布式说话人分离主要包含四个模块:
- VAD
- 语音片段分割
- 说话人特征提取
- 说话人聚类
另外可能会有语音再分割和重叠检测等模块。
语音再分割,是说话人聚类完成后,对说话人边界进行调整,再次分割语音。
重叠部分会影响聚类性能,可以被检测然后丢弃。
片段分割
两种类别:
- 平均分割,比如固定1.5s的窗长和0.75s的重叠;
- 说话人改变检测(SCD),检查说话人切换点,进行切分;
特征提取
和说话人验证的特征提取基本相同,如i-vector,x-vector等;
说话人聚类
说话人聚类指将片段级别的特征分成几组,每组代表一个说话人。
关键:
- 相似度计算,如余弦相似度、PLDA相似度、深度学习相似度等;
- 聚类算法,如k-means聚类,AHC聚类,谱聚类,贝叶斯HMM聚类等;
无监督的聚类算法无法利用标签数据,所以提出将说话人聚类看作半监督学习问题和全监督学习问题。
端到端方法
因为传统聚类算法是无监督的,所以其无法直接最小化话者分离误差,并且难以处理重叠片段。
此外,分布式架构的各模块是独立优化,整体性能难以一致保证。
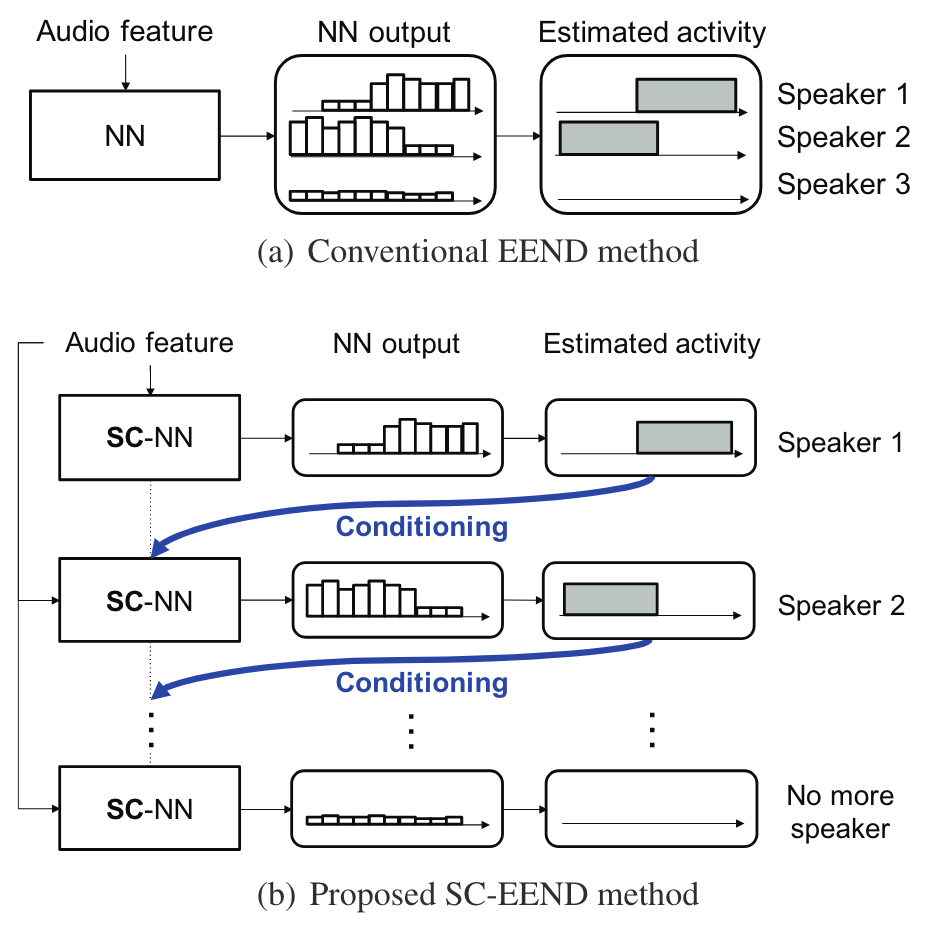
端到端方法:
- 传统方法将其视为每一帧的多分类问题,允许重叠,因为标签序号不定,所以要用PIT训练,说话人最大容量在训练时就确定,且PIT复杂度受说话人数量限制。
- Speaker-wise conditional (SC-EEND)方法,使用编解码器的架构,去逐个生成每个说话人的语音段,同样受PIT限制。
实时话者分离
也可以分成分步式和端到端式。
分布式:将聚类模块替换成可以支持实时推理的NN进行决策;
端到端式:将离线话者分类改成chunk做,但要解决每个chunk说话人排列/序号不一致问题。
多模态话者分离
研究语音和其他模态信息的结合,如语言学信息(音律、文本等),说话人行为(嘴唇等)。
常见的模态融合:
- audio-linguistic
- audio-visual
- 麦克风空间信息
鲁棒说话人识别
主要问题:
- domain mismatch
- noise
解决办法
- domain adaptation
- speech enhancement
- data augmentation
领域适应
domain包括language、channel、phoneme/text、noise等
domain adaptation:使用source domain的数据解决target domain的问题。
target domain也有数据,本文着眼于无标签的target domain训练数据,即无监督damain adaptation。
三种类型的domain adaptation:
- 基于对抗性训练的
- 基于数据重建的
- 基于差异的
基于对抗性训练
目标:对于对抗性训练的领域适应方法旨在于使学习到的源领域的表征$M_s(X_s)$和目标领域的表征$M_t(X_t)$分布一致。
框架:
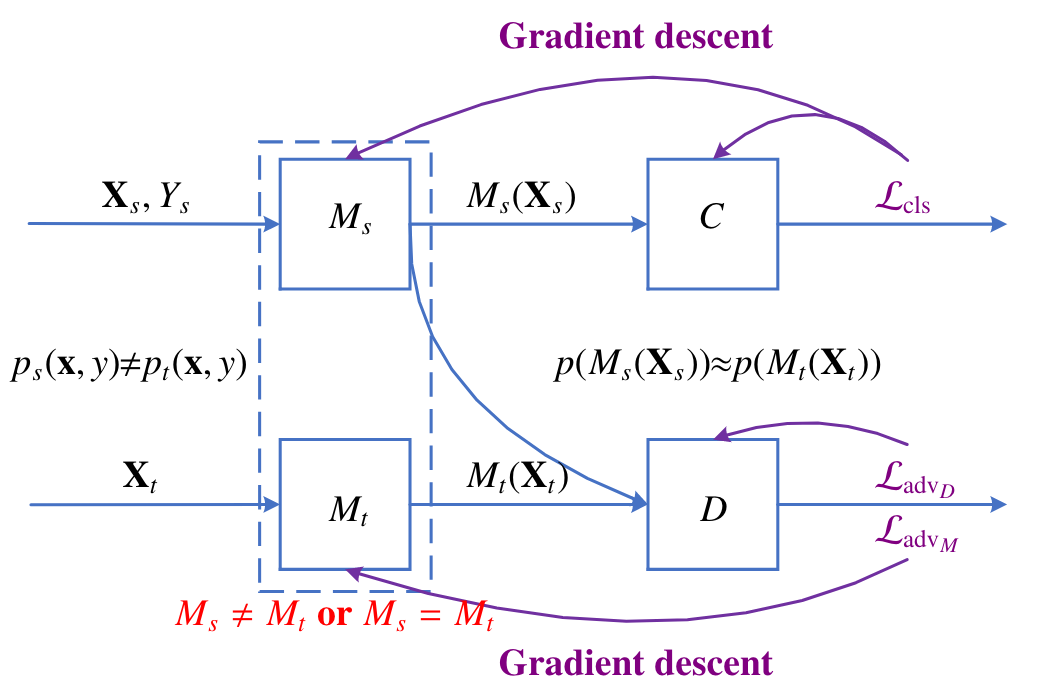
$C$表示说话人分类器,$D$表示领域区分器,对抗性训练通过交替地优化$D$和$M_t$来使得学习到的表征是领域无关的。
“对抗性”思想:$D$的优化目标$\mathcal{L}{adv_D}$是区分两种表征的所属领域(是否相同);$M_t$的优化目标$\mathcal{L}{adv_M}$是让$D$难以区分;
$C$是为了让学习到的表征始终保持说话人区分性。
DANN(Domain-adversarial NN)是领域适应训练的一个具体实现,它增加了一个对网络的限制,即$M_s$和$M_t$共享同一个网络。
基于数据重建
例如:CycleGAN
基于差异
基于差异的领域适应方法使用统计准则,如MMD、CORAL、KL散度等,来对齐源领域和目标领域的统计学分布。
语音增强和去混响
基于深度学习的语音增强和去混响可以分成三类:
- masking-based
- mapping-based
- GAN-based
数据增广
大规模的数据仍然是提高说话人识别鲁棒性的有效方法。
和语音识别常用增广方法基本一致:
- additive noises and reverberation
- speed and pitch perturbation
- spectral augmentation
评价指标
relative equal error rate (EER)
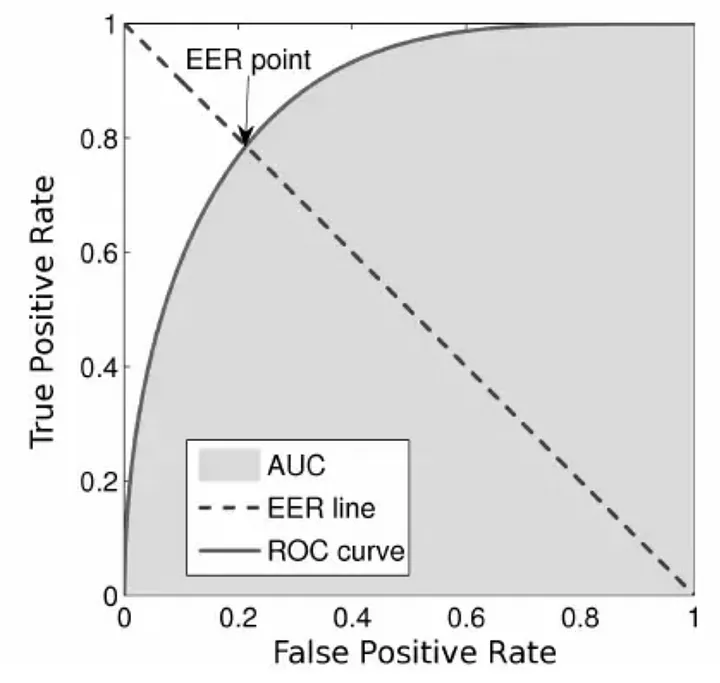
ROC
适用于衡量二分类系统的阈值变化影响。
ROC曲线的坐标系,横坐标为假阳率(FPR,1-负样本的recall),纵坐标为真阳率(TPR,即正样本recall)。
\[TPR = \frac{TP}{TP+FN}=1-FNR\] \[FPR=\frac{FP}{FP+TN}=1-TNR\]EER
等错误率代表FPR和FNR(1-TPR)相等的点,值越小越好。
以一个门禁系统为例,EER平衡的是:
- FNR:有准入资格的人被拒之门外的怒火;
- FPR:无准入资格的人入侵的风险;
标注文件
RTTM
Rich Transcription Time Marked (RTTM) 文件以空格作为各域的分隔符,每行一组数据,包括十个域:
Type– segment type; should always bySPEAKERFile ID– file name; basename of the recording minus extension (e.g.,rec1_a)Channel ID– channel (1-indexed) that turn is on; should always be1Turn Onset– onset of turn in seconds from beginning of recordingTurn Duration– duration of turn in secondsOrthography Field– should always by<NA>Speaker Type– should always be<NA>Speaker Name– name of speaker of turn; should be unique within scope of each fileConfidence Score– system confidence (probability) that information is correct; should always be<NA>Signal Lookahead Time– should always be<NA>
例如:
SPEAKER CMU_20020319-1400_d01_NONE 1 130.430000 2.350 <NA> <NA> juliet <NA> <NA>
SPEAKER CMU_20020319-1400_d01_NONE 1 157.610000 3.060 <NA> <NA> tbc <NA> <NA>
SPEAKER CMU_20020319-1400_d01_NONE 1 130.490000 0.450 <NA> <NA> chek <NA> <NA>
UEM
Un-partitioned evaluation map (UEM)文件用于标记每个记录的评估区域。它的作用是去掉不在评估区域的标注,并不统计评估区域外的系统输出(错误)。
File ID– file name; basename of the recording minus extension (e.g.,rec1_a)Channel ID– channel (1-indexed) that scoring region is on; ignored byscore.pyOnset– onset of scoring region in seconds from beginning of recordingOffset– offset of scoring region in seconds from beginning of recording
例如:
CMU_20020319-1400_d01_NONE 1 125.000000 727.090000
CMU_20020320-1500_d01_NONE 1 111.700000 615.330000
ICSI_20010208-1430_d05_NONE 1 97.440000 697.290000