分布式训练
前言
拓扑结构
Node:N,节点/机器数量
World Size:W,所有节点的进程数量(非卡数)
Local World Size:L,单个节点的进程数量(非卡数)
local rank:单个节点的rank,[0, L-1]
global rank: 全局rank,[0, W-1]
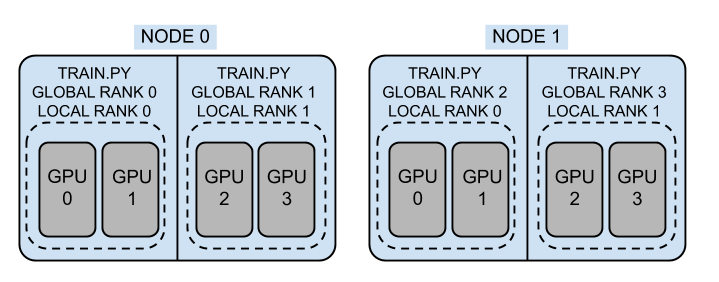
注意进程数不一定要等于GPU数量,上图是1对2。大多数情况不需要模型并行时,1对1。
通讯方式:Point-to-Point Communication
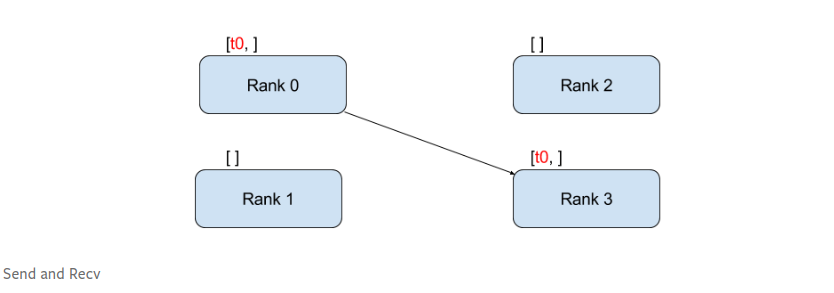
点对点通讯指从一个进程到另一个进程的通讯。
send和recv 是阻塞式,另有非阻塞式isend 和irecv 。
通讯方式:Collective Communication
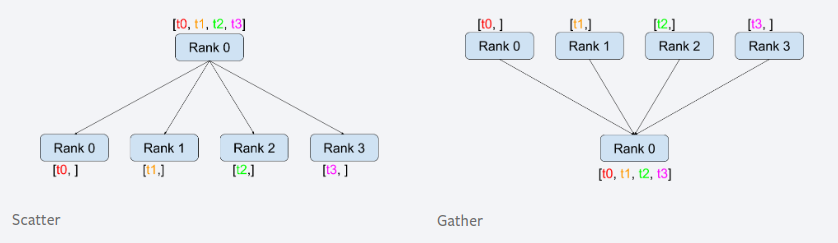
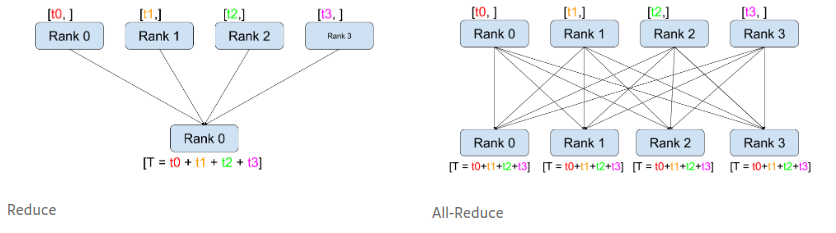
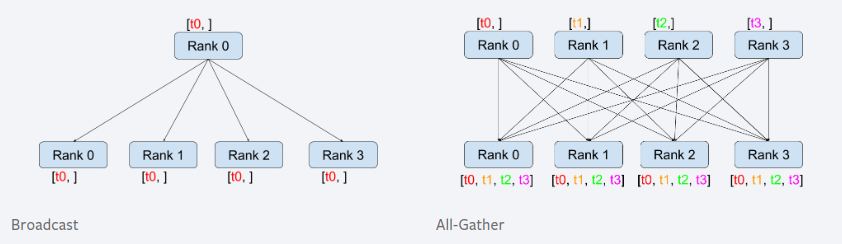
集体通讯,是同一组进程间的通讯,一组进程指所有进程的子集。
torch.distributed包简介
torch.distributed包分成三个主要组件:
- Distributed Data-Parallel Training (DDP): single-program multi-data training paradigm,每个进程使用相同的模型和不同的数据。
- RPC-Based Distributed Training (RPC): 适用于非数据并行的场景,例如分布式pipeline并行、参数服务器范式和 DDP 与其他训练范式的组合。
- Collective Communication (c10d): 支持同组多个进程间传输tensor数据的库,提供集合通信和P2P通信,DDP和RPC均在此基础上构建。DDP使用集体通信接口,RPC使用P2P通信接口。
初始化
本包需要调用init_process_group() 函数进行初始化,初始化后方能进行其他方法调用。
def init_process_group(
backend: Union[str, Backend],
init_method: Optional[str] = None,
timeout: timedelta = default_pg_timeout,
world_size: int = -1,
rank: int = -1,
store: Optional[Store] = None,
group_name: str = "",
pg_options: Optional[Any] = None,
):
(...)
初始化进程组主要有两种方法:
- Specify
store,rank, andworld_sizeexplicitly,其中store用于交换连接/地址信息。 - Specify
init_method(a URL string) which indicates where/how to discover peers. Optionally specifyrankandworld_size, or encode all required parameters in the URL and omit them. If neither is specified,init_methodis assumed to be “env://”. 下文介绍主流的通过设置init_method初始化的方式。
TCP 初始化
需要指定可达的IP地址和world_size ,IP地址必须是rank 0进程的主机。
import torch.distributed as dist
# Use address of one of the machines
dist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',
rank=args.rank, world_size=4)
共享文件系统初始化
需要知道file:// 开头的URL和world_size.
import torch.distributed as dist
# rank should always be specified
dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',
world_size=4, rank=args.rank)
注意,每次使用 file init 方法进行初始化都需要一个全新的空文件才能成功初始化。使用之前的文件,属于意外行为,通常会导致死锁和失败。
环境变量初始化
该方法从环境变量获取需要的配置,给用户提供更高的灵活性。
要配置环境变量包括:
MASTER_PORT- 必须的端口MASTER_ADDR- rank 0的地址,除rank 0外,必须指明WORLD_SIZE- 必须RANK- 必须
此为默认方法,相当于调用init_process_group方法,将参数设置为init_method='env://'
将环境变量设置好后,比如通过export 命令,只需要执行以下代码初始化。
dist.init_process_group(backend="nccl")
Single-Node Data-Parallel Training
最初pytorch提供了torch.nn.DataParallel作为单机多卡的训练的简易入口,但考虑训练性能,已不推荐使用。推荐使用分布式的torch.nn.DistributedDataParallel 进行单机多卡训连。
DataParallel简化了单机多卡训,只需要一行代码将模型包装下,不需要诸如:数据切分、通信等其他配置。
本质上是single-process multi-thread模式,所以性能受GIL限制,不推荐使用。
class DataParallel(Module):
def __init__(self, module, device_ids=None, output_device=None, dim=0):
(...)
前向计算时,复制模型到各个device,然后将输入数据按照batch维度分割成多个chunk,分配给各个模型并行计算(自动等分,保持总batch_size不变)。反向传播,各device上模型的梯度会做sum运算。
调用示例:
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
output = net(input_var) # input_var can be on any device, including CPU
Distributed Data-Parallel Training (DDP)
torch.nn.DistributedDataParallel 提供了简洁的分布式训练接口,不仅支持多记多卡的数据并行训练,也支持模型并行训练。
对于分布式数据并行训练,通常使用以下开发范式:
- 单机多卡训练,虽然可以使用
DataParallel接口,但DistributedDataParallel接口更快; - 多机多卡训练,使用
DistributedDataParallel接口,并使用一个torch.distributed.launch脚本可以简化配置; - 为允许errors和更加弹性,使用
torch.distributed.elastic提供的torchrun接口
DDP的特点:
- 给模型的反向传播增加了hook,在loss backward时调用,自动同步梯度。
- 不会自动切分数据,用户负责正确的数据IO。
- 需要一些设置步骤,例如
init_process_group。 - multi-process模式,无GIL限制。
DDP的接口如下:
class DistributedDataParallel(Module, Joinable):
def __init__(
self,
module,
device_ids=None,
output_device=None,
dim=0,
broadcast_buffers=True,
process_group=None,
bucket_cap_mb=25,
find_unused_parameters=False,
check_reduction=False,
gradient_as_bucket_view=False,
static_graph=False,
delay_all_reduce_named_params=None,
param_to_hook_all_reduce=None,
mixed_precision: Optional[_MixedPrecision] = None,
):
重要参数:
- module:Module,如果是gpu训练,通常先将原始模型to显卡上,然后传给DDP,此时DDP的device_ids无需传参,这样更灵活;
- device_ids:int或者
torch.device的列表。1)对于单卡模型,device_ids只包含对应device id,如[i],或者为None;2) 对于多卡模型或cpu模型,device_ids必须为None。 当device_ids为None时,数据和模型各参数分布由用户自己完成,保证在正确的设备上,详情见后文。 - output_device: 单卡模型输出的device id,默认为device_ids[0],对于多卡模型和CPU模型要设置为None;
- find_unused_parameters:DDP训练模式的隐藏要求是每个节点的梯度必须相同,如果模型中存在部分模块在特定数据中不被启用的情况,则会导致对应模块在各个节点的梯度不同(有的为None),就不会触发梯度平均。find_unused_parameters=True时,DistributedDataParallel会跟踪每个节点的计算图,标记那些没用梯度的参数,并将其梯度视为0,然后再进行梯度平均。
DDP基本范式
DDP本质上是每个进程执行相同的代码,通过rank区分不同进程。
对于单机多卡,所有进程运行在同一台机器上,rank和gpu编号可以直接对应,比如rank 0 对应 cuda: 0。
对于多机多卡,进程运行在不同一台机器上,global级别的rank和gpu编号无法直接对应,需要进行转换,比如 rank % ngpus_node。
以下以单机多卡为例,进程和卡数1比1,意味着rank和gpu编号一一对应。
首先初始化设置,此处通过TCP初始化,并手动传入rank和world size。
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
初始化完成后,对原始模型进行DDP包装。用户需要自己处理进程和gpu设备的对应关系。
在DDP的构造函数中,其将rank0的原始模型参数广播到其他进程,所以每个进程的模型参数是相同的。
这里理想化数据IO,并设定每个进程处理单卡。
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
# 默认rank和gpu编号一一对应
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
调用时,多个进程执行相同的代码,此处使用torch.multiprocessing.spawn简化多次执行代码:
def run_demo(demo_fn, world_size):
# demo_fn is called as demo_fn(i, *args), where i is the process index
# which is equivalent to rank
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
assert n_gpus >= 2, f"Requires at least 2 GPUs to run, but got {n_gpus}"
world_size = n_gpus
run_demo(demo_basic, world_size)
如果要进行checkpoint的保存和读取,需要注意一定要在保存进程结束后,才允许其他进程进行读取:
def demo_checkpoint(rank, world_size):
print(f"Running DDP checkpoint example on rank {rank}.")
setup(rank, world_size)
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"
if rank == 0:
# All processes should see same parameters as they all start from same
# random parameters and gradients are synchronized in backward passes.
# Therefore, saving it in one process is sufficient.
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# Use a barrier() to make sure that process 1 loads the model after process
# 0 saves it.
dist.barrier()
# configure map_location properly
map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}
ddp_model.load_state_dict(
torch.load(CHECKPOINT_PATH, map_location=map_location))
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
# Not necessary to use a dist.barrier() to guard the file deletion below
# as the AllReduce ops in the backward pass of DDP already served as
# a synchronization.
if rank == 0:
os.remove(CHECKPOINT_PATH)
cleanup()
总结:
- 先决条件:DDP依赖c10d的
ProcessGroup进行通讯,所以在构建DDP之前先通过torch.distributed.init_process_group实例化ProcessGroup - 构造:DDP构造函数需要引用本地模型
Module,并将rank 0进程的state_dict()广播到其他进程,保持状态一致,然后每个进程创建一个本地Reducer,负责梯度同步。 - 前向:DDP将输入数据传递给本地模型,进行前向计算。
- 反向:通过
Reducer同步梯度 - 优化器:对优化器而言,DDP和本地训练没有区别。
- checkpint保存/读取:可以用
dist.barrier()避免其他进程提前执行读取代码;
DDP和模型并行结合
大模型需要放到多卡上训练,此时仍然可以和DDP结合。
示例直接在模型定义中,设置模型参数由两卡分摊:
class ToyMpModel(nn.Module):
def __init__(self, dev0, dev1):
super(ToyMpModel, self).__init__()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
数据需要在两卡之间手动拷贝,DDP可以直接套用:
def demo_model_parallel(rank, world_size):
print(f"Running DDP with model parallel example on rank {rank}.")
setup(rank, world_size)
# setup mp_model and devices for this process
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)
optimizer.zero_grad()
# outputs will be on dev1
outputs = ddp_mp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(dev1)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
调用的时候,单进程两卡,所以world size是ngpus的1/2。
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
assert n_gpus >= 2, f"Requires at least 2 GPUs to run, but got {n_gpus}"
world_size = n_gpus
world_size = n_gpus//2
run_demo(demo_model_parallel, world_size)
launching and configuring DDP
被弃用,建议使用torchrun 。
无论如何启动DDP应用,每个进程都需要知道rank和world size,为此,pytorch提供torch.distributed.launch 进行快捷启动。其负责在每个训练节点上生成多个分布式训练进程。
如果要使用launch ,DDP应用必须遵守两点规范:
- 为单个worker提供一个入口函数,也就是说不要用
torch.multiprocessing.spawn启动所有子进程;
例如,以下DDP应用提供spmd_main入口函数:
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int, default=0)
parser.add_argument("--local_world_size", type=int, default=1)
args = parser.parse_args()
spmd_main(args.local_world_size, args.local_rank)
- 必须使用环境变量去初始化process group;
在spmd_main 函数中,process group初始化时仅使用了backend参数,其余参数通过环境变量获取,环境变量由launch设置。
def spmd_main(local_world_size, local_rank):
# These are the parameters used to initialize the process group
env_dict = {
key: os.environ[key]
for key in ("MASTER_ADDR", "MASTER_PORT", "RANK", "WORLD_SIZE")
}
print(f"[{os.getpid()}] Initializing process group with: {env_dict}")
dist.init_process_group(backend="nccl")
print(
f"[{os.getpid()}] world_size = {dist.get_world_size()}, "
+ f"rank = {dist.get_rank()}, backend={dist.get_backend()}"
)
demo_basic(local_world_size, local_rank)
# Tear down the process group
dist.destroy_process_group()
给定了local rank和local word size, demo_basic方法推导出每个进程的device_ids,初始化DistributedDataParallel 模型。
def demo_basic(local_world_size, local_rank):
# setup devices for this process. For local_world_size = 2, num_gpus = 8,
# rank 0 uses GPUs [0, 1, 2, 3] and
# rank 1 uses GPUs [4, 5, 6, 7].
n = torch.cuda.device_count() // local_world_size
device_ids = list(range(local_rank * n, (local_rank + 1) * n))
print(
f"[{os.getpid()}] rank = {dist.get_rank()}, "
+ f"world_size = {dist.get_world_size()}, n = {n}, device_ids = {device_ids}"
)
model = ToyModel().cuda(device_ids[0])
ddp_model = DDP(model, device_ids)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_ids[0])
loss_fn(outputs, labels).backward()
optimizer.step()
上例在调用时,假定机器的卡数local world size必须相同,所以device_ids只会有一个元素。
调用命令,以单机8进程8卡为例,--nnode表示节点数,,--node_rank表示当前脚本执行的节点,--nproc_per_node表示local world size,
python /path/to/launch.py --nnode=1 --node_rank=0 --nproc_per_node=8 example.py --local_world_size=8
也可以单机单进程单卡:
python /path/to/launch.py --nnode=1 --node_rank=0 --nproc_per_node=1 example.py --local_world_size=1
torch.distributed.elastic
该模块是为了使程序可以从错误中恢复训练,例如常见的OOM。
为什么不用try-except : DDP同步时使用AllReduce操作,如果try-except 异常处理的结果不符合AllReduce操作的期望值,就可能造成同步崩溃或者阻塞。
该模块提供torchrun 命令,进一步简化了DDP训练代码,支持错误容忍和弹性扩缩容,相比于torch.distributed.launch多了以下功能:
- 某个woker失败后,可以通过重启所有worker来优雅的处理;
RANK和WORLD_SIZE会自动分配;- 节点的数量可以在设定范围内弹性地变化;
初始化设置需要的环境变量,可以通过torchrun传参设置,DDP代码只需要调用dist.init_process_group() 完成初始化。也就是说,使用torchrun 就意味着默认使用env://方式初始化通讯。
torchrun的调用如下:
torchrun
--nnodes=$NUM_NODES
--nproc-per-node=$NUM_TRAINERS
--max-restarts=3
--rdzv-id=$JOB_ID
--rdzv-backend=c10d
--rdzv-endpoint=$HOST_NODE_ADDR
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)
其中
--nnodes和--nproc-per-node: 可以理解成要求用户在nnodes个机器上执行torchrun及后续命令,torchrun内部会fork nproc个进程执行用户训练脚本。--rdzv-id: A unique job id,为了防止几个不同的job实例跑在同一台机器上造成混淆。--rdzv-backend: 通信后端,推荐c10d;--rdzv-endpoint: 通信接口,通常host:port形式;
另外--standalone选项开启后,意味着单节点单JOB训练,不需要设置上面三个参数。
DDP代码可以访问的环境变量包括:
WORLD_SIZE: 关键变量;RANK:global rank,关键变量;LOCAL_RANK:单个节点里的本地rank,方便和gpu编号映射;GROUP_RANK:每个节点当作一个group,某个节点所处的rank;ROLE_RANK:LOCAL_WORLD_SIZE: 等于torchrun的--nproc-per-node值。ROLE_WORLD_SIZEMASTER_ADDR: rank 0所在主机的全域名,用于初始化通信;MASTER_PORT:同上,通信端口;TORCHELASTIC_RESTART_COUNTTORCHELASTIC_MAX_RESTARTSTORCHELASTIC_RUN_ID: 等价于run_id,就是job id;PYTHON_EXEC
代码示例:
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
model = ToyModel().to(device_id)
ddp_model = DDP(model, device_ids=[device_id])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_id)
loss_fn(outputs, labels).backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
demo_basic()
调用时,以2机8卡为例,elastic_ddp.py是上例的文件名:
torchrun --nnodes=2 --nproc_per_node=8 --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR:29400 elastic_ddp.py
用户只需要在集群的两个节点上,分别执行该命令,即可完成通信和分布式训练。
Distributed Training with Uneven Inputs
分布式训练时,对于无法均分的数据集,如果某个worker的数据先于其他worker读完,那么该worker可能会挂起或者引发错误。
Join是一个上下文管理器,包装了训练Loop,让先读完数据的worker可以影响未读完数据的worker。
__init__(self, joinables: List[Joinable], enable: bool = True, throw_on_early_termination: bool = False)
Joinable对象是训练Loop中参与每轮集体通信的对象,提供了hook来决定如何等待未结束训练Loop的worker,例如DistributedDataParallel 和 ZeroRedundancyOptimizer
DistributedDataParallel 实现的方式是先结束的worker挂起,等待其他worker结束训练Loop。
示例:
BACKEND = "nccl"
WORLD_SIZE = 2
NUM_INPUTS = 5
def worker(rank):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(BACKEND, rank=rank, world_size=WORLD_SIZE)
model = DDP(torch.nn.Linear(1, 1).to(rank), device_ids=[rank])
# Rank 1 gets one more input than rank 0
inputs = [torch.tensor([1]).float() for _ in range(NUM_INPUTS + rank)]
num_inputs = 0
with Join([model]):
for input in inputs:
num_inputs += 1
loss = model(input).sum()
loss.backward()
print(f"Rank {rank} has exhausted all {num_inputs} of its inputs!")
def main():
mp.spawn(worker, nprocs=WORLD_SIZE, join=True)
if __name__ == "__main__":
main()
上例中,rank 0要比rank 1提前结束数据读取,此时rank 0会等待,直到rank 1也读完数据,所以最终打印结果顺序是随机的,说明两个rank的训练Loop是同时结束的。
Rank 0 has exhausted all 5 of its inputs!
Rank 1 has exhausted all 6 of its inputs!
Join([model]) 中的model被DDP包装了,变成了一个可等待的对象Joinable 。
RPC-Based Distributed Training
很多训练场景不使用数据并行模式,例如强化学习训练、模型参数并行等;
torch.distributed.rpc四个核心支柱:
- RPC:支持在远程worker上执行给定函数,获取执行结果。
- RRef:一个远程对象的引用,帮助管理远程对象的生命周期
- Distributed Autograd: 使自动求导引擎支持多机多卡
- Distributed Optimizer: 支持多机多卡的优化器
RPC
使用RPC前需要使用torch.distributed.rpc.init_rpc()初始化。
def init_rpc(
name,
backend=None,
rank=-1,
world_size=None,
rpc_backend_options=None,
):
(...)
该初始化方法未提供MASTER_ADDR 和MASTER_PORT 接口,所以需要其他方法指定,例如通过环境变量。
torch.distributed.rpc.rpc_sync() 方法可以在指定woker即to上执行函数。
@_require_initialized
def rpc_sync(to, func, args=None, kwargs=None, timeout=UNSET_RPC_TIMEOUT):
(...)
返回值是func执行的结果。
调用示例如下:
>>> # export MASTER_ADDR=localhost export MASTER_PORT=5678
>>> # On worker 0:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> ret = rpc.rpc_sync("worker1", torch.add, args=(torch.ones(2), 3))
>>> rpc.shutdown()
>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()
torch.distributed.rpc.remote 方法在指定wokerto上执行函数func,并且立即返回一个指向远程对象(即func的返回值)的RRef 。这意味着该远程对象实际存在于to 上,其他woker(即调用者)仅保留其引用。
@_require_initialized
def remote(to, func, args=None, kwargs=None, timeout=UNSET_RPC_TIMEOUT):
(...)
torch.distributed.rpc.shutdown 方法关闭RPC agent,可以强制关闭,也可以等待所有通讯结束后关闭。
RRef
RRef类的实例是一个远程woker上对象的引用,比如,Tensor,但尚不支持CUDA Tensor 。远程对象实体存在于远程worker上,但可以被显式传输到本地worker上。
Distributed Autograd Framework
该模块提供一个基于RPC的分布式自动求导框架,即应用程序可以通过RPC传输梯度tensor。在前向过程中,模块记录下梯度存储tensor被RPC发送的时间点,然后在反向传播时,使用这些时间点同步梯度。
Distributed Optimizer
分布式优化器的构造函数需要Optimizer() 对象和一堆要优化参数的RRef ,然后为每个RRef 的持有者创建一个Optimizer() 实例,用其更新参数。
分布式优化器包装了本地优化器,并提供了统一的接口step() 。
Collective Communication
本节使用c10d实现DistributedDataParallel的功能。
下例简单实现一个分布式的SGD,让每个进程计算一部分输入数据,然后平均梯度。partition_dataset()方法根据rank对数据集划分,使每个进程处理不同的数据。
""" Distributed Synchronous SGD Example """
def run(rank, size):
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = Net()
optimizer = optim.SGD(model.parameters(),
lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
for epoch in range(10):
epoch_loss = 0.0
for data, target in train_set:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
epoch_loss += loss.item()
loss.backward()
average_gradients(model)
optimizer.step()
print('Rank ', dist.get_rank(), ', epoch ',
epoch, ': ', epoch_loss / num_batches)
average_gradients() 方法简单地平均了全局梯度。
""" Gradient averaging. """
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= size
Fully Sharded Data Parallel(FSDP)
FSDP 是数据并行方式的一种,它在DDP的rank上对模型参数、优化器状态和梯度进行分片处理。
工作机制
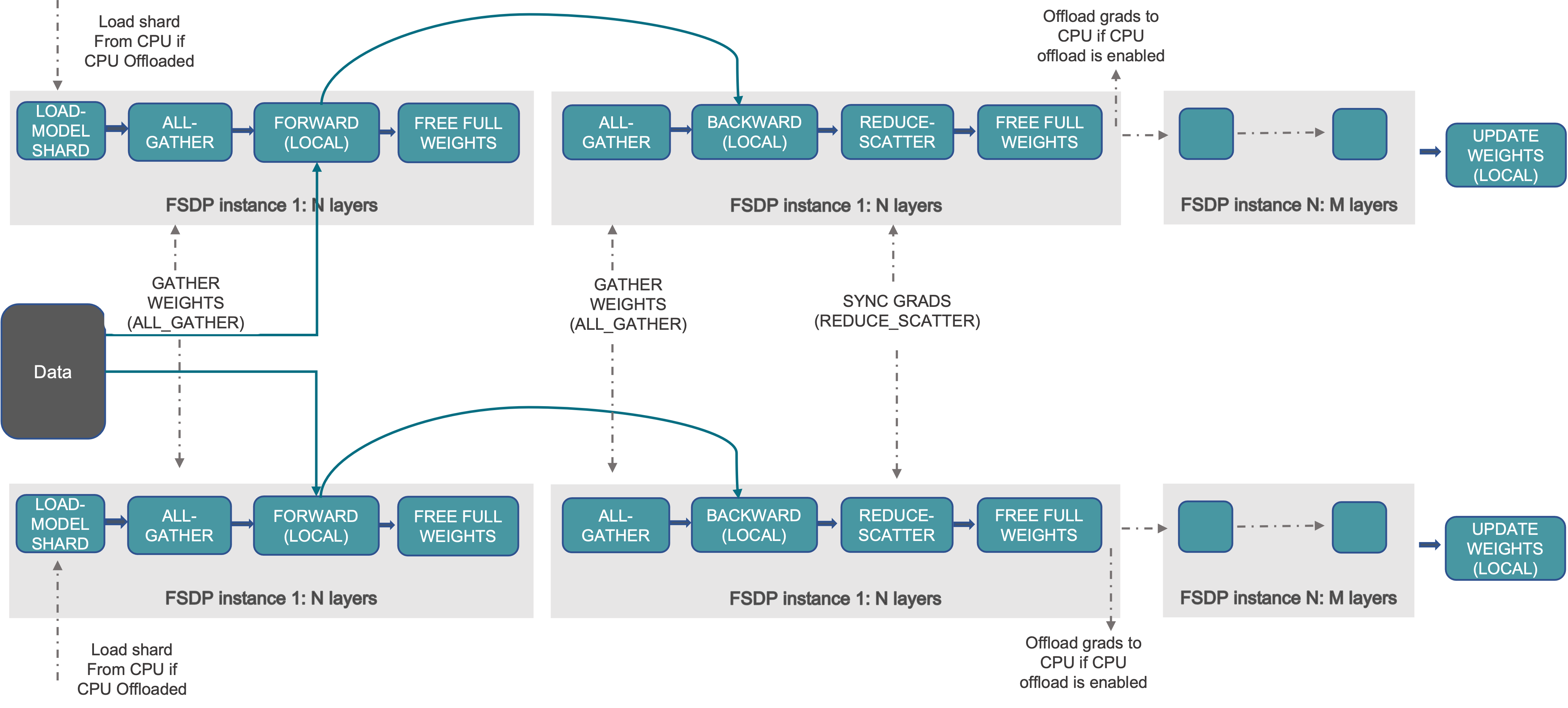
FSDP工作流程如下:
构造器:
- Shard model parameters and each rank only keeps its own shard
前向:
- Run all_gather to collect all shards from all ranks to recover the full parameter in this FSDP unit
- Run forward computation
- Discard parameter shards it has just collected
后向:
- Run all_gather to collect all shards from all ranks to recover the full parameter in this FSDP unit
- Run backward computation
- Run reduce_scatter to sync gradients
- Discard parameters.
Sharding机制解释:
分片机制并不是指将一个20层的模型分成两个10层的子模型,而是将模型的参数tensor在不同的GPU上进行切分。这意味着每个GPU只存储整个模型参数的一个子集,从而减少单个GPU上的内存占用。
FSDP unit:
分片后的参数需要allgather进行恢复,那么是逐个的恢复,还是逐层的恢复,还是逐块恢复,或者整个模型一起恢复?如果整个模型一起allgather,那么切片毫无意义。FSDP unit就是限制allgather恢复操作的范围。假设一个100层的模型,被放到5个FSDP unit,每个拥有20层。那么前向计算时,第一个FSDP unit里的前20层参数被allgather恢复,进行计算,然后参数被丢弃,进行下一个FSDP unit里的恢复和计算。
最优划分FSDP unit具有挑战性,FSDP允许用户指定划分策略,通过auto_wrap_policy 传入。
FSDP和DDP的联系:
- DDP训练中,每个进程/工作节点拥有模型的一个副本,并行处理不同的数据,最终使用 allreduce 操作在不同工作节点上汇总梯度。
- FSDP训练中,每个工作节点拥有模型的不同切片,并行处理不同的数据,使用reduce_scatter操作同步梯度。内部过程,需要使用all-gather操作恢复完整权重,计算完成后reduce_scatter操作汇总并分发梯度。
- 在“数据并行”部分FSDP和DDP一模一样,区别只是GPU存储的模型参数量,通过封装底层的通讯过程,让FSDP训练流程和DDP几乎相同。
使用方法
fsdp是ddp的一种形式,基本设置和ddp相同。
模型要用FSDP()装饰
model = Net().to(rank)
model = FSDP(model)
保存参数时要注意,需要在每个rank上调用 state_dict,然后在rank 0 上保存完整参数。
if args.save_model:
# use a barrier to make sure training is done on all ranks
dist.barrier()
states = model.state_dict()
if rank == 0:
torch.save(states, "mnist_cnn.pt")