Megatron入门:数据管线
TLDR
Megatron的数据集同样继承自torch.utils.data.Dataset ,是map-style的索引数据集,不是iter-style 的迭代器数据集。因为数据集只存储元信息(索引, 长度等),懒加载实际数据,所以map-style 也可以支持超大数据集IO。
底层输入数据的格式使用特制的二进制格式,拆分成元信息和实际数据,即.idx和.bin 后缀文件,Megatraon提供了工具预先打包成该二进制格式。另有实现SFTDataset支持JSONL格式的文本文件输入。
同样通过torch.utils.data.DataLoader 和训练Loop传递数据。
依靠分布式采样器,来进行DP数据切分。
同一个TP组数据,都从TP组的rank0获取,确保数据一致。
Dataset UML
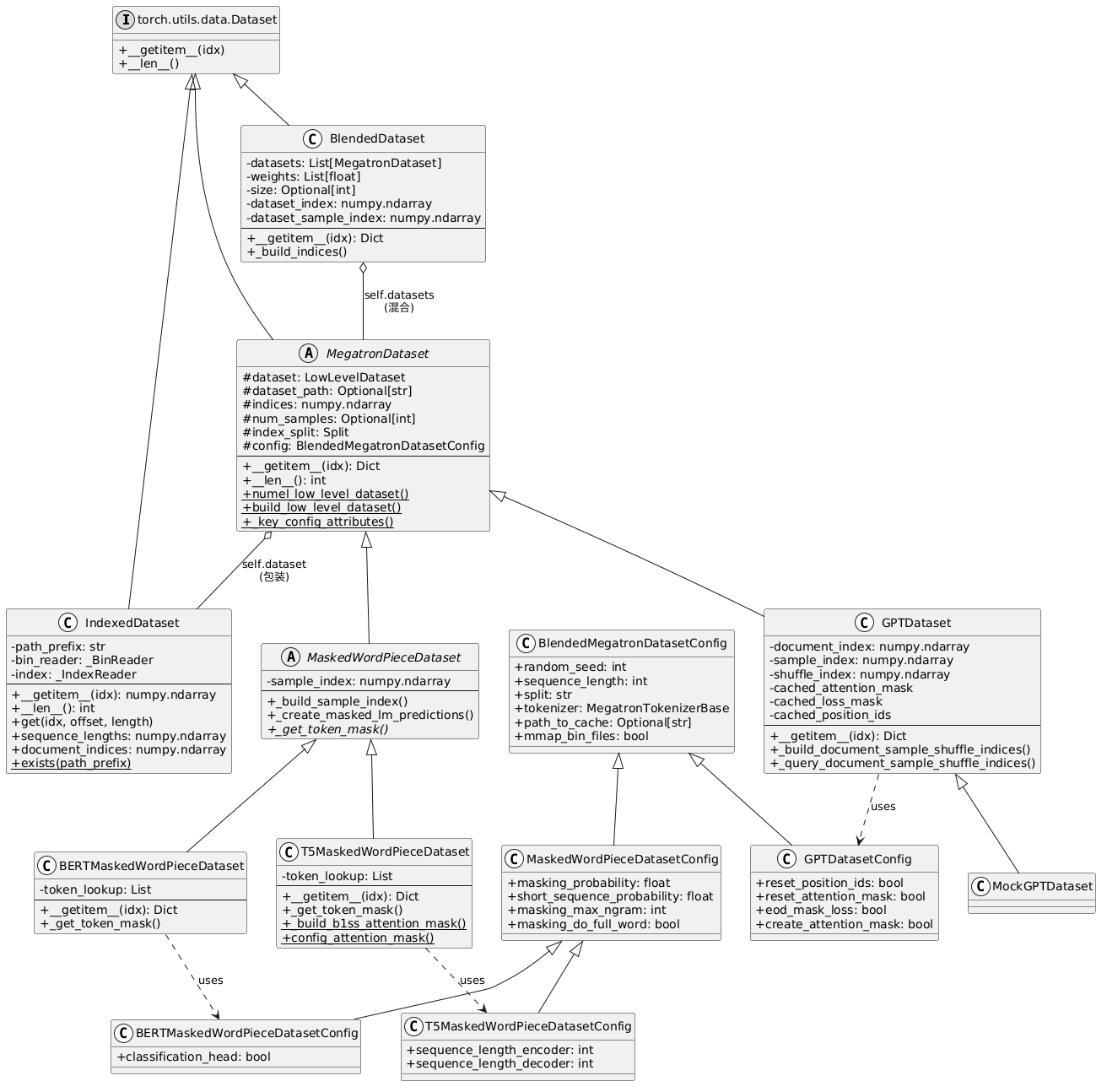
构建数据加载的核心class:
BlendedMegatronDatasetConfig: 可扩展的数据集配置文件描述类,用来参数化BlendedMegatronDatasetBuilder,进而构建MegatronDatasetandBlendedDataset.BlendedMegatronDatasetBuilder: 创建数据集的工具类,返回高层级的数据集对象,可以进行数据集切分;IndexedDataset:最底层的数据集类,读取硬盘上格式化好的二进制文件数据;MegatronDataset:高层级数据集抽象类,根据不同的训练/推理实现具体的子类, 如GPTDataset,SFTDataset,BERTDataset,T5Dataset等;BlendedDataset:对多个数据集进行组合,支持多种子组合后采样方式;
Data loading:实现
IndexedDataset
IndexedDataset 是 Megatron 数据系统的最底层数据集类,直接读取磁盘上的 .idx 和 .bin 文件,为上层 GPTDataset/BlendedDataset 提供高效的 token 数据存储和访问。
核心职责:
- 数据存储: .bin 文件存储 token 数据,.idx 文件存储索引元信息
- 高效访问: 支持 mmap、S3、MSC 等多种读取方式
- 索引管理:提供序列长度、文档边界等元数据
- 序列模式:支持多模态数据的模式标记
与 GPTDataset 的关系
IndexedDataset: 底层存储,提供原始 token 数据
│
│ 提供:
│ - sequence_lengths: 每个序列长度
│ - document_indices: 文档边界
│ - get(idx, offset, length): 读取 token 片段
│
▼
GPTDataset: 中层包装,构建训练样本
│
│ 添加:
│ - document_index: 文档 shuffle 顺序
│ - sample_index: 样本边界
│ - shuffle_index: 样本 shuffle
│ - tokens/labels: 输入/目标分离
│ - attention_mask, loss_mask, position_ids
│
▼
训练器: 使用训练样本
文件结构
.idx和.bin 都是特制的二进制文件结构,这个格式最早来自 Facebook/Meta(Fairseq 项目),后被 NVIDIA Megatron-LM 采用并重写。
{prefix}.idx 存储索引文件(元信息),{prefix}.bin 存储数据文件(token 序列)。
┌─────────────────────────────────────────────────────────────────┐
│ .idx 文件结构 │
├─────────────────────────────────────────────────────────────────┤
│ 偏移 │ 大小 │ 内容 │ 说明 │
├─────────┼──────────┼───────────────────────┼────────────────────┤
│ 0 │ 9 bytes │ "MMIDIDX\x00\x00" │ Magic Header │
│ 9 │ 8 bytes │ version (uint64) │ 版本号 = 1 │
│ 17 │ 1 byte │ dtype_code (uint8) │ 数据类型编码 │
│ 18 │ 8 bytes │ sequence_count │ 序列总数 │
│ 26 │ 8 bytes │ document_count │ 文档总数 │
│ 34 │ N×4 bytes│ sequence_lengths │ 每个序列的长度 │
│ 34+N×4 │ N×8 bytes│ sequence_pointers │ 每个序列的字节偏移 │
│ ... │ D×8 bytes│ document_indices │ 文档边界索引 │
│ ... │ N×1 bytes│ sequence_modes (可选) │ 多模态模式标记 │
└─────────┴──────────┴───────────────────────┴────────────────────┘
例如:
sequence_lengths = [100, 50, 200, 80] (4 个序列)
sequence_pointers = [0, 400, 600, 1400] (每个序列在 .bin 中的字节起始位置)
document_indices = [0, 2, 4] (文档边界:序列 0-1 是文档1,序列 2-3 是文档2)
.bin 文件是连续的 token 数据:
┌──────────────────────────────────────────────────────────┐
│ .bin 文件结构 │
├──────────────────────────────────────────────────────────┤
│ 偏移 │ 内容 │ 说明 │
├─────────┼─────────────────────┼──────────────────────────┤
│ 0 │ token[0:100] │ 序列 0 的 token │
│ 400 │ token[0:50] │ 序列 1 的 token │
│ 600 │ token[0:200] │ 序列 2 的 token │
│ 1400 │ token[0:80] │ 序列 3 的 token │
└─────────┴─────────────────────┴──────────────────────────┘
注意:
- 偏移是字节偏移,不是 token 偏移
- 偏移 = pointer[i] = sum(lengths[0:i]) * dtype_size
- dtype_size 通常是 2 (uint16) 或 4 (int32)
vs Parquet
Parquet:
- 列式存储,适合表格数据
- 压缩高效
- 不适合变长序列
IndexedDataset:
- 行式存储,适合变长 token 序列
- 无压缩,直接 mmap
vs HDF5
HDF5:
- 通用科学数据格式
- 支持复杂数据结构、压缩、属性
- 库体积大,依赖重
IndexedDataset:
- 仅支持 1D token 序列 + 索引
- 无压缩(训练时避免解压开销)
- 纯 NumPy/C 实现,轻量
Megatron 提供专门的预处理脚本:
# 预处理文本数据为 IndexedDataset 格式
python tools/preprocess_data.py \
--input my_text.txt \
--output-prefix my_dataset \
--tokenizer-type GPT2BPETokenizer \
--vocab-file vocab.json \
--merge-file merges.txt \
--workers 32
# 生成:
# my_dataset.idx
# my_dataset.bin
关键方法
__init__— 初始化
def __init__(
self,
path_prefix: str, # 文件前缀 "data/my_dataset" → .idx/.bin
multimodal: bool = False, # 是否多模态
mmap: bool = True, # 是否 mmap 读取 .bin
object_storage_config: ..., # S3/MSC 配置
fast_cache_load: bool = False, # 快速加载模式
sequences_per_dataset: ..., # 预设序列/文档数
dtype_code: int = None, # 数据类型编码
):
# 初始化 bin_reader 和 index
self.initialize(...)
initialize— 初始化读取器
def initialize(self, path_prefix, multimodal, mmap, object_storage_config, ...):
idx_path = path_prefix + ".idx"
bin_path = path_prefix + ".bin"
# 选择 BinReader
if mmap:
self.bin_reader = _MMapBinReader(bin_path) # mmap 本地文件
elif object_storage_config:
self.bin_reader = _S3BinReader(...) # S3 流式读取
else:
self.bin_reader = _FileBinReader(bin_path) # 普通文件读取
# 读取索引
self.index = _IndexReader(idx_path, multimodal, ...)
__getitem__— 获取序列
def __getitem__(self, idx):
if isinstance(idx, (int, numpy.integer)):
# 单个序列
pointer, length, mode = self.index[idx]
sequence = self.bin_reader.read(dtype, count=length, offset=pointer)
return (sequence, mode) if mode is not None else sequence
elif isinstance(idx, slice):
# 切片:必须是连续的
start, stop, step = idx.indices(len(self))
if step != 1:
raise ValueError("必须是连续切片")
# 批量读取
lengths = self.index.sequence_lengths[idx]
total_length = sum(lengths)
start_pointer = self.index.sequence_pointers[start]
# 一次读取所有 token,然后按长度切分
raw = self.bin_reader.read(dtype, count=total_length, offset=start_pointer)
sequences = numpy.split(raw, list(accumulate(lengths[:-1])))
return sequences
get— 获取序列片段
def get(self, idx, offset=0, length=None):
"""
获取序列的子片段,GPTDataset 常用此方法
Args:
idx: 序列索引
offset: token 偏移(从第几个 token 开始)
length: 读取多少个 token
Returns:
numpy.ndarray: token 数据
"""
pointer, sequence_length, mode = self.index[idx]
if length is None:
length = sequence_length - offset
# 计算字节偏移
pointer += offset * DType.size(self.index.dtype)
sequence = self.bin_reader.read(dtype, count=length, offset=pointer)
return (sequence, mode) if mode is not None else sequence
GPTDataset
GPTDataset 是用于 GPT 风格语言模型预训练的数据集类,包装 IndexedDataset 并提供样本构建、索引管理、掩码生成等功能。
三个关键构建参数:总样本数N,序列长度和随机种子R。
核心职责:
- 样本索引构建:将原始文档/序列切分为固定长度的训练样本
- 随机打乱:支持文档级和样本级 shuffle
- tokens/labels 分离:Casual语言模型的输入/目标分离
- 掩码生成:attention_mask、loss_mask、position_ids
- Padding:样本不足时填充至目标序列长度
数据抽象
GPTDataset 通过三层索引,将多个独立文档虚拟化为一个随机顺序的”大文档”,然后顺序切分为固定长度样本,再打乱样本顺序供训练使用。
GPTDataset 的数据抽象是:
原始数据(多个独立文档)
│
│ Document Index: 重复 E 次 + shuffle 文档顺序
▼
虚拟"扁平化大文档"(文档顺序随机,但文档内部 token 顺序不变)
│
│ Sample Index: 按固定长度顺序切分
▼
N 个顺序排列的样本(样本可能跨文档边界)
│
│ Shuffle Index: 样本级打乱
▼
训练时随机访问的样本
示例
原始文档:
D0 = [t0, t1, t2, t3, t4] (5 tokens)
D1 = [t5, t6, t7, t8] (4 tokens)
D2 = [t9, t10, t11, t12] (4 tokens)
Document Index (E=2, shuffle 后):
[D1, D0, D2, D0, D2, D1] ← 文档顺序被打乱
虚拟"大文档"(按 Document Index 顺序拼接):
[t5, t6, t7, t8, t0, t1, t2, t3, t4, t9, t10, t11, t12,
t0, t1, t2, t3, t4, t9, t10, t11, t12, t5, t6, t7, t8]
Sample Index (seq_length=5,顺序切分):
Sample 0: [t5, t6, t7, t8, t0] ← D1 全部 + D0 开头
Sample 1: [t1, t2, t3, t4, t9] ← D0 剩余 + D2 开头
Sample 2: [t10, t11, t12, t0, t1] ← D2 剩余 + D0 开头
Sample 3: [t2, t3, t4, t9, t10] ← D0 剩余 + D2 开头
Sample 4: [t11, t12, t5, t6, t7] ← D2 剩余 + D1 开头
Sample 5: [t8] ← D1 剩余(不足一个样本)
Shuffle Index (打乱样本顺序):
[3, 0, 4, 1, 2] ← 训练时按此顺序访问
最终获取样本:
gpt_dataset[0] → shuffle_index[0]=3 → Sample 3
gpt_dataset[1] → shuffle_index[1]=0 → Sample 0
gpt_dataset[2] → shuffle_index[2]=4 → Sample 4
...
关键属性
class GPTDataset(MegatronDataset):
# 索引(构建于初始化时)
self.document_index # 文档顺序数组(支持多 epoch 重复)
self.sample_index # 样本边界(doc_id, offset)
self.shuffle_index # 样本级随机打乱映射
# 缓存(可选)
self.cached_attention_mask
self.cached_loss_mask
self.cached_position_ids
关键方法
1. __getitem__(idx) — 获取训练样本
def __getitem__(self, idx: Optional[int]) -> Dict[str, torch.Tensor]:
# 1. 从底层 IndexedDataset 获取原始 token
text, _ = self._query_document_sample_shuffle_indices(idx)
# 2. tokens/labels 分离(左到右模型)
tokens = text[:-1] # 输入
labels = text[1:] # 目标(下一个 token)
# 3. 生成掩码和 position_ids
attention_mask, loss_mask, position_ids = _get_ltor_masks_and_position_ids(...)
# 4. 返回训练样本
return {
"tokens": tokens,
"labels": labels,
"attention_mask": attention_mask,
"loss_mask": loss_mask,
"position_ids": position_ids,
}
2. _build_document_sample_shuffle_indices() — 构建三层索引
def _build_document_sample_shuffle_indices(self):
# 计算每个 epoch 的 token 数
num_tokens_per_epoch = self._get_num_tokens_per_epoch()
num_epochs = self._get_num_epochs(num_tokens_per_epoch)
# [1] document_index: 文档顺序(多 epoch 重复 + shuffle)
document_index = _build_document_index(self.indices, num_epochs, ...)
# [2] sample_index: 每个样本的起止文档和偏移
sample_index = helpers.build_sample_idx(
sequence_lengths, document_index, sequence_length, ...
)
# [3] shuffle_index: 样本级随机打乱
shuffle_index = _build_shuffle_index(num_samples, ...)
return document_index, sample_index, shuffle_index
三层索引的作用:
shuffle_index[idx] → 打乱后的样本索引
sample_index[sample_idx] → (doc_id, offset) 样本边界
document_index[doc_id] → 原始文档 ID
IndexedDataset.get(doc_id) → 原始 token 数据
分布式训练有多个 rank(GPU 进程),每个 rank 都需要相同的索引。如果打开path_to_cache 那么:
1. Rank 0 构建索引并保存到缓存文件
2. 其他 Rank 从缓存文件加载(并行加载)
3. 缓存文件用 hash 唯一标识,确保正确性
避免所有 GPU 进程重复构建索引。
3. _query_document_sample_shuffle_indices(idx) — 查询索引获取原始数据
def _query_document_sample_shuffle_indices(self, idx):
# 应用 shuffle
idx = self.shuffle_index[idx]
# 获取样本边界
doc_beg, offset_beg = self.sample_index[idx]
doc_end, offset_end = self.sample_index[idx + 1]
# 从 IndexedDataset 获取 token
if doc_beg == doc_end:
# 样本在单个文档内
sample = self.dataset.get(doc_beg, offset=offset_beg, length=...)
else:
# 样本跨越多个文档
sample_parts = [self.dataset.get(doc_i, ...) for doc_i in range(doc_beg, doc_end+1)]
sample = numpy.concatenate(sample_parts)
# Padding
if len(sample) < sequence_length:
sample = numpy.pad(sample, ...)
return sample, document_ids
SFTDataset
和GPTDataset处于同一层级的类,用于SFT训练,支持JSONL格式数据输入。
因为输入是JSONL文本格式,所以底层读取数据的类是SFTLowLevelDataset 。
每一行格式如下:
# 一场对话多轮
[{"role": "system", "content": "something"}, {"role": "user", "content": "something1"}, {"role": "assistant", "content": "something2"}, ]
# 也可以是多场对话
[{"role": "system", "content": "..."}, {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}, {"role": "system", "content": "..."}, {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."},]
重要方法
_split_conversations方法把一条列表里多场对话拆分成多条;
def _split_conversations(self, merged_conversations):
"""
将合并的多个对话拆分成独立的对话
Args:
merged_conversations: 一个 jsonl 行中的所有 messages
例如:[
{"role": "system", "content": "..."}, # 对话1开始
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."},
{"role": "system", "content": "..."}, # 对话2开始
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."},
]
Returns:
split_conversations: 拆分后的对话列表
例如:[
[{"role": "system", ...}, {"role": "user", ...}, {"role": "assistant", ...}],
[{"role": "system", ...}, {"role": "user", ...}, {"role": "assistant", ...}],
]
"""
split_conversations = []
current = []
for msg in merged_conversations:
# 遇到 system message,开始新的对话
if msg["role"] == "system":
if current: # 如果之前有积累的对话,保存它
split_conversations.append(current)
current = [msg] # 开始新对话
else:
current.append(msg) # 继续积累当前对话
# 保存最后一个对话
if current:
split_conversations.append(current)
return split_conversations
__getitem__核心取数方法,数据被打包成Time-Head-Dimension(THD)格式。
def __getitem__(self, idx: int) -> Dict[str, Any]:
tokenizer = self.config.tokenizer
pack_length = self.config.sequence_length
# ============== 1. 获取对话数据 ==============
# indices[idx] → 底层数据集的真实索引
merged_conversations = self.dataset[int(self.indices[idx % len(self.indices)])]
split_conversations = self._split_conversations(merged_conversations)
# ============== 2. 初始化 pack 变量 ==============
pack_tokens = [] # 打包后的所有 tokens
pack_targets = [] # 打包后的所有 targets (labels)
pack_positions = [] # 打包后的所有 position_ids
cu_seqlens = [0] # 累积序列长度 (THD 格式)
eod = tokenizer.eod # EOS token
pad = tokenizer.pad # Padding token
# ============== 3. Pack 多个对话 ==============
for conversation in split_conversations:
# 3.1 使用 tokenizer 处理对话
tokens, targets = tokenizer.tokenize_conversation(
conversation,
return_target=True, # 返回 targets (masked prompts)
add_generation_prompt=False # 不添加生成 prompt
)
tokens_list = tokens.tolist()
targets_list = targets.tolist()
# 3.2 添加到 pack
pack_tokens.extend(tokens_list)
pack_targets.extend(targets_list)
# 3.3 position_ids (reset_position_ids=False 时使用简单递增)
assert not self.config.reset_position_ids
pack_positions.extend(range(len(tokens_list)))
# 3.4 Context Parallel padding (可选)
if self.config.context_parallel_size > 1:
pad_granularity = self.config.context_parallel_size * 2
mod_token_count = len(pack_tokens) % pad_granularity
if mod_token_count != 0:
pad_len = pad_granularity - mod_token_count
extend_with_padding(pack_tokens, pack_targets, pack_positions, pad_len)
# 3.5 记录 cu_seqlens (当前对话结束位置)
cu_seqlens.append(len(pack_tokens))
# 3.6 Truncate (如果超过 pack_length)
if len(pack_tokens) >= pack_length + 1:
max_body = pack_length
pack_tokens = pack_tokens[:max_body]
pack_targets = pack_targets[:max_body]
pack_tokens.append(pad)
pack_targets.append(pad)
pack_positions = pack_positions[:pack_length + 1]
cu_seqlens[-1] = len(pack_tokens) - 1
break
# ============== 4. Padding (如果不足 pack_length) ==============
if len(pack_tokens) < pack_length + 1:
pad_len = pack_length + 1 - len(pack_tokens)
extend_with_padding(pack_tokens, pack_targets, pack_positions, pad_len)
cu_seqlens[-1] = len(pack_tokens) - 1
# 验证长度
assert len(pack_tokens) == pack_length + 1
assert len(pack_targets) == pack_length + 1
assert len(pack_positions) == pack_length + 1
# ============== 5. 构造训练样本 ==============
# Shift: tokens[:-1] 作为输入, targets[1:] 作为 labels
input_ids = torch.tensor(pack_tokens[:-1], dtype=torch.int64)
labels = torch.tensor(pack_targets[1:], dtype=torch.int64)
position_ids = torch.tensor(pack_positions[:-1], dtype=torch.int64)
# ============== 6. Loss Mask ==============
loss_mask = torch.ones(pack_length, dtype=torch.float32)
loss_mask[labels == pad] = 0.0 # Mask padding tokens
loss_mask[labels == IGNORE_INDEX] = 0.0 # Mask prompts (system/user)
# ============== 7. cu_seqlens 和 max_seqlen ==============
cu_seqlens = torch.tensor(cu_seqlens, dtype=torch.int32)
# 计算 max_seqlen (最大单个序列长度)
adjacent_diffs = cu_seqlens[1:] - cu_seqlens[:-1]
max_seqlen = adjacent_diffs.max()
# ============== 8. 返回 ==============
return {
'tokens': input_ids, # 输入 tokens
'labels': labels, # 目标 labels (masked prompts)
'loss_mask': loss_mask, # Loss mask (只计算 assistant)
'position_ids': position_ids, # Position IDs
'cu_seqlens': cu_seqlens, # THD 格式的序列边界
'max_seqlen': max_seqlen, # 最大序列长度
}
THD格式是让不同序列的输入更紧凑。
传统格式:
│ Batch of sequences: │
│ seq0: [t0, t1, t2, t3, PAD, PAD, PAD, PAD] (shape: B×S) │
│ seq1: [t4, t5, t6, t7, t8, PAD, PAD, PAD] │
│ seq2: [t9, t10, t11, PAD, PAD, PAD, PAD, PAD] │
│ │
│ 缺点:大量 padding,浪费计算
THD格式:
│ Packed sequence: │
│ tokens: [t0, t1, t2, t3, t4, t5, t6, t7, t8, t9, t10, t11]│
│ cu_seqlens: [0, 4, 9, 12] ← 序列边界 │
│ max_seqlen: 5 ← 最大序列长度 │
│ cu_seqlens[i] 表示第 i 个序列的起始位置 │
│ seq0: tokens[0:4] = [t0, t1, t2, t3] │
│ seq1: tokens[4:9] = [t4, t5, t6, t7, t8] │
│ seq2: tokens[9:12] = [t9, t10, t11] │
│ │
│ 优点:无 padding,高效计算
BlendedDataset
BlendedDataset 是顶层组合类,用于按权重混合多个 MegatronDataset,支持多数据源训练。
BlendedDataset 使用两层索引映射样本:dataset_index 和 dataset_sample_index。
核心职责:
- 多数据集混合:按 weights 比例从多个数据集采样
- 索引映射:构建
dataset_index和dataset_sample_index - 透明访问:
__getitem__返回格式与底层 MegatronDataset 一致 - 缓存支持:索引可缓存,避免重复构建
整体架构
BlendedDataset
│
│ dataset_index[idx] → dataset_id
│ dataset_sample_index[idx] → sample_id
│
├── datasets[0] ── GPTDataset_0
│ │
│ └── IndexedDataset_0
│
├── datasets[1] ── GPTDataset_1
│ │
│ └── IndexedDataset_1
│
└── datasets[2] ── GPTDataset_2
│
└── IndexedDataset_2
关键属性
class BlendedDataset:
self.datasets # List[MegatronDataset] - 底层数据集列表
self.weights # List[float] - 混合权重(归一化后)
self.size # Optional[int] - 总样本数(None 表示穷尽采样)
self.dataset_index # numpy.ndarray - 每个 sample 来自哪个数据集
self.dataset_sample_index # numpy.ndarray - 在该数据集中的样本索引
关键方法
_build_indices— 核心索引构建。
def _build_indices(self) -> Tuple[numpy.ndarray, numpy.ndarray]:
"""
构建两个索引数组:
- dataset_index: 每个 sample 来自哪个数据集
- dataset_sample_index: 在该数据集中的样本索引
"""
# ========== 1. 延迟加载模式(defer_npy_index_mmap)==========
if self.config.defer_npy_index_mmap:
# 不立即构建,只记录路径,后续 __getitem__ 时再 mmap 加载
self.path_to_dataset_index = "cache/{hash}-dataset_index.npy"
self.path_to_dataset_sample_index = "cache/{hash}-dataset_sample_index.npy"
return None, None
# ========== 2. 检查缓存是否存在 ==========
path_to_cache = self.config.path_to_cache
if path_to_cache:
# 缓存文件路径
path_to_description = "cache/{hash}-description.txt"
path_to_dataset_index = "cache/{hash}-dataset_index.npy"
path_to_dataset_sample_index = "cache/{hash}-dataset_sample_index.npy"
# fast_cache_load: 跳过检查,直接认为缓存存在
# 否则:检查三个文件是否都存在
cache_hit = (
True if self.config.fast_cache_load
else all(os.path.isfile(...) for ... in [description, index, sample_index])
)
else:
cache_hit = False
# ========== 3. 缓存不存在:Rank 0 构建 ==========
if not path_to_cache or (not cache_hit and torch.distributed.get_rank() == 0):
# 【分支 A】固定大小模式:size 指定
if self.size is not None:
dataset_index = numpy.zeros(self.size, dtype=numpy.int16)
dataset_sample_index = numpy.zeros(self.size, dtype=numpy.int64)
helpers.build_blending_indices(
dataset_index,
dataset_sample_index,
self.weights, # 归一化的 float
len(self.datasets),
self.size,
)
# 【分支 B】穷尽模式:size = None
else:
size = sum(self.weights) # weights 是整数列表
dataset_index = numpy.zeros(size, dtype=numpy.int16)
dataset_sample_index = numpy.zeros(size, dtype=numpy.int64)
helpers.build_exhaustive_blending_indices(
dataset_index,
dataset_sample_index,
self.weights, # 整数列表
len(self.datasets),
)
# ========== 4. 校验:不能过度采样 ==========
# 统计每个数据集被采样的次数
dataset_indices, dataset_sizes = numpy.unique(dataset_index, return_counts=True)
for _index, _size in zip(dataset_indices, dataset_sizes):
if len(self.datasets[_index]) < _size:
raise IndexError(
f"数据集 {_index} 只有 {len(self.datasets[_index])} 个样本,"
f"但被请求采样 {_size} 次,超出容量!"
)
# ========== 5. 保存缓存 ==========
if path_to_cache:
os.makedirs(path_to_cache, exist_ok=True)
with open(path_to_description, "wt") as writer:
writer.write(self.unique_description)
numpy.save(path_to_dataset_index, dataset_index)
numpy.save(path_to_dataset_sample_index, dataset_sample_index)
return dataset_index, dataset_sample_index
# ========== 6. 缓存存在:所有 Rank 加载 ==========
else:
# 使用 mmap_mode="r" 延迟加载,不立即读入内存
dataset_index = numpy.load(path_to_dataset_index, mmap_mode="r")
dataset_sample_index = numpy.load(path_to_dataset_sample_index, mmap_mode="r")
return dataset_index, dataset_sample_index
__getitem__— 获取样本
def __getitem__(self, idx: int) -> Dict:
# 1. 获取数据集 ID 和样本索引
dataset_id = self.dataset_index[idx] # 哪个数据集
dataset_sample_id = self.dataset_sample_index[idx] # 该数据集中的样本
# 2. 从底层 MegatronDataset 获取样本
sample = self.datasets[dataset_id][dataset_sample_id]
# 3. 添加 dataset_id 字段并返回
return {"dataset_id": dataset_id, **sample}
BlendedMegatronDatasetBuilder
BlendedMegatronDatasetBuilder 是构建 BlendedDataset 和 MegatronDataset 的工厂类。
负责:
- 处理 train/valid/test 多个 split
- 处理多数据源混合(blend)
- 分布式构建(Rank 0 先构建,其他 Rank 后加载缓存)
- 并行构建多个数据集
使用示例
from megatron.core.datasets import (
BlendedMegatronDatasetBuilder,
BlendedMegatronDatasetConfig,
GPTDataset,
GPTDatasetConfig,
)
# 创建配置
config = BlendedMegatronDatasetConfig(
random_seed=42,
sequence_length=2048,
blend=(["data/wiki", "data/books", "data/code"], [0.5, 0.3, 0.2]),
split_matrix=[(0.0, 0.9), (0.9, 0.95), (0.95, 1.0)],
tokenizer=tokenizer,
)
# 创建 Builder
builder = BlendedMegatronDatasetBuilder(
cls=GPTDataset,
sizes=[100000, 10000, 1000], # train/valid/test 目标样本数
is_built_on_rank=lambda: True,
config=config,
)
# 构建数据集
datasets = builder.build()
# [train_dataset, valid_dataset, test_dataset]
# train_dataset 是 BlendedDataset
# 包含 wiki_gpt_train, books_gpt_train, code_gpt_train
# 按权重 [0.5, 0.3, 0.2] 混合
关键属性
class BlendedMegatronDatasetBuilder:
self.cls # MegatronDataset 类型(如 GPTDataset)
self.sizes # 每个 split 的目标样本数 [train_size, valid_size, test_size]
self.is_built_on_rank # 判断当前 Rank 是否需要构建
self.config # BlendedMegatronDatasetConfig 配置
关键方法
1.build 方法流程
def build(self) -> List[Optional[TopLevelDataset]]:
"""
返回 [train_dataset, valid_dataset, test_dataset]
每个 split 可能是:
- None: 不构建该 split
- MegatronDataset: 单数据源
- BlendedDataset: 多数据源混合
"""
datasets = self._build_blended_dataset_splits()
# 校验
for dataset in datasets:
if dataset is not None:
if isinstance(dataset, BlendedDataset):
assert dataset.size == len(dataset)
elif isinstance(dataset, MegatronDataset):
assert dataset.num_samples <= len(dataset)
return datasets
MegatronPretrainingSampler
核心职责:
- DP 分片: 按 data_parallel_rank 将样本分配给不同 DP ranks
- 顺序遍历: 从 consumed_samples 开始顺序遍历,支持断点恢复
- Micro Batch 生成: 每次 yield 一个 micro batch 的索引列表
- Drop Last: 丢弃不完整的最后一个 batch
与 PyTorch DistributedSampler 的对比
| 特性 | PyTorch DistributedSampler | MegatronPretrainingSampler |
|---|---|---|
| 分片方式 | 随机打乱后按 rank 分片 | 顺序遍历后按 rank 分片 |
| 断点恢复 | 不直接支持(需手动调整) | 直接支持(consumed_samples) |
| Batch 结构 | 每个 rank 独立 batch | 按 global batch 分组,每个 rank 取一部分 |
| Pipeline Parallel | 不兼容 PP | 兼容 PP(PP 需要确定性顺序) |
| 随机性 | 有 shuffle | 无 shuffle(依赖数据集 shuffle_index) |
关键属性
class MegatronPretrainingSampler:
def __init__(
self,
total_samples, # 数据集总样本数
consumed_samples, # 已消费样本数(断点恢复用)
micro_batch_size, # 每个 micro batch 的样本数
data_parallel_rank, # 当前 rank 在 DP 组内的位置
data_parallel_size, # DP 组大小
drop_last=True, # 是否丢弃不完整 batch
):
self.total_samples = total_samples
self.consumed_samples = consumed_samples
self.micro_batch_size = micro_batch_size
self.data_parallel_rank = data_parallel_rank
self.micro_batch_times_data_parallel_size = micro_batch_size * data_parallel_size
self.drop_last = drop_last
注意DP划分的数据,不受TP size和PP size的影响。开启 Pipeline Parallel 后,Sampler 的逻辑完全不变。只是 forward_backward_func 调用 num_microbatches 次 next(data_iterator),每次获取一个 micro batch,组成流水线调度。
关键方法
__iter__ 获取分布式索引
def __iter__(self):
batch = []
# 1. 从 consumed_samples 开始顺序遍历(支持断点恢复)
for idx in range(self.consumed_samples, self.total_samples):
batch.append(idx)
# 2. 当 batch 大小达到 micro_batch_times_data_parallel_size 大小时
if len(batch) == self.micro_batch_times_data_parallel_size:
# 【关键】3. 每个 DP rank 只取属于自己的那部分
start_idx, end_idx = self.get_start_end_idx()
yield batch[start_idx:end_idx]
batch = []
# 4. 处理最后一个不完整 batch
if len(batch) > 0 and not self.drop_last:
start_idx, end_idx = self.get_start_end_idx()
yield batch[start_idx:end_idx]
def get_start_end_idx(self):
"""
计算当前 DP rank 在 micro_batch_times_data_parallel_size 中的索引范围
例如:
micro_batch_size = 4
dp_rank = 2
start_idx = 2 * 4 = 8
end_idx = 8 + 4 = 12
返回 batch[8:12],即第 2 个 DP rank 的 micro batch
"""
start_idx = self.data_parallel_rank * self.micro_batch_size
end_idx = start_idx + self.micro_batch_size
return start_idx, end_idx
和train loop传递数据
例如,在pretrain 方法流程中,通过调用build_train_valid_test_data_iterators 获取Dataset。
# training.py: pretrain
def pretrain(train_valid_test_dataset_provider, model_provider, ...):
# 1. 初始化 Megatron
initialize_megatron()
# 2. 构建模型和 optimizer
model, optimizer, opt_param_scheduler = setup_model_and_optimizer(model_provider)
# 3. 构建数据迭代器
timers('train/valid/test-data-iterators-setup').start()
train_data_iterator, valid_data_iterator, test_data_iterator = (
build_train_valid_test_data_iterators(train_valid_test_dataset_provider)
)
timers('train/valid/test-data-iterators-setup').stop()
# 4. 开始训练
iteration, num_flops = train(
forward_step_func,
model,
optimizer,
opt_param_scheduler,
train_data_iterator, # ← 传入 iterator
valid_data_iterator,
...
)
build_train_valid_test_data_loaders 通过用户提供的provider获得dataset,然后封装成dataloader。
# training.py: build_train_valid_test_data_loaders
def build_train_valid_test_data_loaders(provider):
args = get_args()
# 1. 构建数据集
train_ds, valid_ds, test_ds = build_train_valid_test_datasets(provider)
# 2. 构建 DataLoader
if args.skip_train:
train_dataloader = None
else:
train_dataloader = build_pretraining_data_loader(
train_ds,
args.consumed_train_samples # 断点恢复时的已消费样本数
)
valid_dataloaders = [build_pretraining_data_loader(valid_d, ...) for valid_d in valid_ds]
test_dataloader = build_pretraining_data_loader(test_ds, 0)
return train_dataloader, valid_dataloaders, test_dataloader
用户定义 train_valid_test_dataset_provider ,调用Megatron提供的Dataset接口构建数据集。
# pretrain_gpt.py
def train_valid_test_datasets_provider(train_val_test_num_samples):
"""用户提供的数据集构建函数"""
# 构建 GPTDatasetConfig
config = GPTDatasetConfig(
random_seed=args.seed,
sequence_length=args.seq_length,
blend=(["data/wiki", "data/books"], [0.7, 0.3]), # 数据源和权重
split=args.split, # train/valid/test 比例
tokenizer=tokenizer,
...
)
# 使用 BlendedMegatronDatasetBuilder
train_ds, valid_ds, test_ds = BlendedMegatronDatasetBuilder(
GPTDataset, # 数据集类型
train_val_test_num_samples, # [train_size, valid_size, test_size]
is_dataset_built_on_rank, # 判断是否在当前 rank 构建
config,
).build()
return train_ds, valid_ds, test_ds