Aho–Corasick算法在语音识别应用
Aho–Corasick算法是一种字符串搜索算法,可以在输入文本中定位有限字符串集的元素。
例如,待搜索的字符串集为“{a, aa, aaa, aaaa}”,输入文本是“aaaa”,Aho–Corasick算法能发现四个字符串均存在于输入文本中。
该算法将待搜索的字符串编译成有限状态机(FST),主体是字符串组成的前缀树,然后在节点间增加额外的连接,这些额外的连接允许当前字符串匹配失败后快速跳转到下一个字符串。
如果待搜索的字符串可以提前获得,那么有限状态机的编译是一次性的。
执行搜索时,逐字符的在状态机上跳转,直到搜索到最后一个字符。此时搜索时间是线性的,跟输入文本长度和待搜索字符的串数量有关。
原理和步骤
假设待搜索的字符串集为:{a, ab, bab, bc, bca, c, caa}.
前缀树
首先构建一个前缀树,如图所示,暂且只关注节点和黑色的弧。

根节点表示空,黑色弧表示字符串的下一个字符,子节点表示从根节点到当前节点,所有黑色弧上的字符组成的字符串。有些子节点表示完整的字符串,如图中白色节点,称作“输出节点”。有些只是是待搜索字符串的子串,如图中灰色节点。
如左下的第二个“(ab)”节点,表示待搜索的字符串“ab”。中间下数第二个灰色节点“(b)”,只是字符串“bc”和“bca”的子串,当搜索到“b”不能表示搜索成功,必须继续搜索到“bc”或“bca”才算成功。
蓝色弧
然后构建蓝色的“后缀弧”,或者称作“失败弧”,指向当前字符串的“最长后缀子串“。例如,对节点“(caa)”,它的子字符串有“aa“,”a“和”“。其中最长后缀子串是“a“,所以蓝色弧从“(caa)”节点指向“(a)”节点。
蓝色弧的作用是当搜索失败时,能够快速回退到已经匹配的最长子串,继续搜索。例如,当搜索已经匹配到字符串”ca“时,下一个输入字符是”b“,因为”cab“不存在,所以没有匹配的字符串,那就回退到字符串”a“开始继续搜索,成功匹配”ab“。
蓝色弧可以通过广度优先遍历算法进行构建。因为蓝色弧总是从树的下层节点指向上层某个节点。具体来说,对于某个节点X,要找到它可能存在的蓝色弧对应的目标节点,步骤如下:
- 根节点的子节点,一定有蓝色弧指向根节点,因为空字符串是所有字符串的最长后缀子串。
- 找到节点X的父节点对应的蓝色弧指向节点,称作X的后缀节点,设为Y;
- 判断Y的子节点Z的最后一个字符是否和X的最后一个字符相同;
- 如果相同,那么构建蓝色弧从X指向Z,即Z是X的最长后缀子串,结束;
- 如果不同,那么沿着节点Y的蓝色弧找到新的节点,设为新的Y;
- 重复步骤3,直到找到最长后缀子串,或者到达根节点;
以节点“(bca)”为例,其父节点是“(bc)”,蓝色弧指向节点“(c)”,“(c)”的子节点“(ca)”,其和“(bca)”最后字符相同,那么“(ca)”就是“(bca)”的最长后缀子串,蓝色弧从“(bca)“指向”(ca)“。
绿色弧
最后构建绿色的“输出弧”,绿色弧表示当起始节点表示的字符串匹配成功时,目标节点表示的字符串同样也匹配成功。它和蓝色弧的区别在于,蓝色弧指向的目标节点可能只是一个子串,即非输出节点。但绿色弧指向的节点必定是一个完整字符串,即输出节点。
绿色弧的作用是,在沿着输入文本逐字符搜索过程中,可以快速输出当前步所有被匹配的字符串。只需要不断沿着绿弧遍历所有目标节点即可。
构建绿色弧,只需要沿着起始节点的蓝色弧,检查目标节点是否输出节点,如果是,则创建起始节点到该目标节点的绿色弧,然后结束。如果不是则沿着蓝色弧继续检查下一个目标节点,直到到达根节点为止。
例如,节点“(bca)”到节点“(a)”的绿色弧是这样建立的:先沿着蓝色弧到“(ca)”,其不是一个输出节点,继续沿着蓝色弧到“(a)”,其是一个输出节点,建立“(bca)”到“(a)”的绿色弧,结束。
搜索过程
对输入文本逐个字符的搜索,沿着状态机的弧,在各个节点上跳转。步骤如下:
- 首先,从根节点出发,尝试黑色弧;
- 如果下一个字符满足黑色弧跳转条件,则沿着黑色弧跳转到子节点,继续搜索下一个字符;
- 否则,沿着蓝色弧跳转到后缀节点,然后继续步骤2;
- 每跳转到一个节点,输出当前节点搜索到的所有字符串,即输出当前节点(如果是输出节点的话)和沿着绿色弧可到达的所有节点所代表的字符串。
- 重复步骤1~4,直到搜索到最后一个字符;
例如,假设输入文本是“abccab“,那么搜索过程如下:
| Node | Remaining string | Output:end position | Transition | Output |
|---|---|---|---|---|
| () | abccab | start at root | ||
| (a) | bccab | a:1 | () to child (a) | Current node |
| (ab) | ccab | ab:2 | (a) to child (ab) | Current node |
| (bc) | cab | bc:3, c:3 | (ab) to suffix (b) to child (bc) | Current Node, Dict suffix node |
| (c) | ab | c:4 | (bc) to suffix (c) to suffix () to child (c) | Current node |
| (ca) | b | a:5 | (c) to child (ca) | Dict suffix node |
| (ab) | ab:6 | (ca) to suffix (a) to child (ab) | Current node |
在语音识别应用
Aho–Corasick算法可用于在语音识别解码时,增强热词的解码分数,以提高热词的识别率(召回率)。
例如,假设热词列表为 “HE/SHE/SHELL/HIS/THIS”,热词增强分数为+1,可以构建如下状态机。
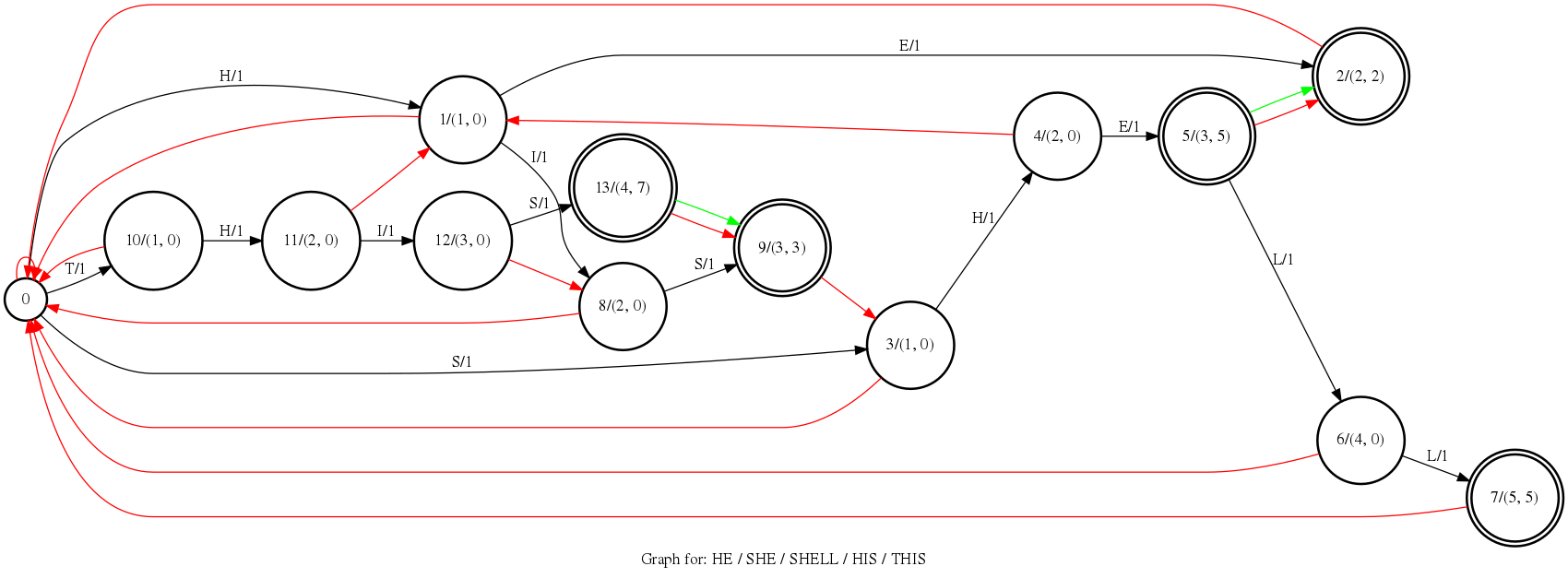
图中黑色弧表示从父节点匹配下一个字符跳转至子节点,红色弧表示“失败弧”即“后缀弧”,绿色弧表示”输出弧“。
和上文不同,黑色弧上除了字符外,还多了分数,表示对匹配到的字符进行增强,这里是对热词的每个字符均匀的+1。每个节点上有两个分数,分别表示当前分数和输出分数。前者表示一个热词匹配到部分时的增强分数,例如,节点11表示匹配到“TH”时,增强分数为2。后者表示当前节点所有输出分数之和,即此时所有可完整匹配到热词的增强分数之和。例如,节点5可匹配到两个热词“SHE”和“HE”,输出分数为5。
当沿着失败弧跳转时,需要减去一定分数,表示回退之前的热词增强。例如,从节点8沿失败弧跳转到节点0,需要减去全部的当前分数,即-2,意味着从头开始搜索热词。从节点12跳转到节点8,需要减去两个节点的当前分数之差,即-1,意味着从”THI“回退到”HI“,需要减去1分。
除了当前分数和输出分数外,还有一个累积分数(total boost score),指在搜索过程中,截止到当前步对输入文本增强的所有分数。沿着黑色弧跳转会不断增加此分数,沿着红色失败弧跳转,会削减分数。
假设输入文本是“SHELF”,那么在上述状态机上搜索路径如下:
| Frame | Boost score | Total boost score | Graph state | Matched hotwords |
|---|---|---|---|---|
| init | 0 | 0 | 0 | |
| 1 | 1 | 1 | 3 | |
| 2 | 1 | 2 | 4 | |
| 3 | 1 + 5 | 8 | 5 | HE, SHE |
| 4 | 1 | 9 | 6 | |
| 5 | -4 | 5 | 0 | |
| finalize | 0 | 5 | 0 |
第一步,从起始节点0到节点3,匹配到字符“S”,+1分,累积分数为1。
第二步,从节点1跳转到节点3,新增匹配字符“H”,+1分,当前匹配到子串”SH”,累积分数为2。
第三步,从节点4跳转到节点5,新增匹配字符“E”,+1分,当前匹配到子串“SHE”。节点5是输出节点,意味着此时匹配到两个完整热词“HE”和“SHE”,所以节点5的输出的分是+5。因此此时累积得分是2+1+5=8。
第四步,从节点5跳转到节点6,新增匹配字符“L”,+1分,匹配到子串“SHEL”,累积分数9。
第五步,下一个字符是“F”,无法沿黑色弧跳转,只能沿失败弧跳转回节点0,节点6的当前得分是4,需要-4,因此回退到节点0后,累积分数是9-4=5;
重点说明下,累积得分由所有已匹配完整热词得分和潜在热词子串得分组成,因此,第三步时,已经匹配到的子串“SHE”的累积得分8分,包括两个完整热词”HE“和”SHE“的得分,共5分,和当前潜在热词子串“SHE”的得分,3分。
状态机的实现
有限状态机是一个图结构,可用邻接表数组高效表示。
节点
图的节点就是有限状态机的状态。
class ContextState:
"""The state in ContextGraph"""
def __init__(
self,
id: int,
token: int,
token_score: float,
node_score: float,
output_score: float,
is_end: bool,
):
关键属性如下:
- id:节点的id;
- token:token id,表示沿着满足该token的黑色弧可达此节点;
- token_score:单个token的得分
- node_score:当前分数,用于失败时回退分数;
- output_score: 输出分数,表示当前节点所有匹配到的热词分数之和;
- is_end:标识该节点是否是输出节点;
- next:黑色弧可达节点,可以多个;
- fail: 失败弧可达节点,仅1个;
- output: 输出弧可达节点,仅1个;
根节点比较特殊,下文单独介绍。
图
热词图即热词构成的有限状态机。
class ContextGraph:
def __init__(self,
context_list_path: str,
symbol_table: Dict[str, int],
bpe_model: str = None,
context_score: float = 6.0):
关键属性介绍如下:
- context_list:热词的token id序列,利用context_list_path和symbol_table,以及可能需要的bpe_model转换而来;
- context_score: 单个token的增强得分;
- num_nodes:节点数量,根节点不算;
- root:根节点,直接在实例化图时创建;
self.root = ContextState(
id=self.num_nodes,
token=-1,
token_score=0,
node_score=0,
output_score=0,
is_end=False,
)
构建图
创建根节点后,接着将热词都编译成图。
首先用context_list的热词编译成前缀树,完成黑色弧的建立。
for tokens in token_ids:
node = self.root
for i, token in enumerate(tokens):
if token not in node.next:
self.num_nodes += 1
is_end = i == len(tokens) - 1
node_score = node.node_score + self.context_score
node.next[token] = ContextState(
id=self.num_nodes,
token=token,
token_score=self.context_score,
node_score=node_score,
output_score=node_score if is_end else 0,
is_end=is_end,
)
node = node.next[token]
node_score是当前子串的增强得分,所以下一个节点的node_score是当前node_score和context_score之和。
output_score在编译前缀树阶段,就等于node_score或者为0,后面会进行更新。
然后继续构建失败弧。
利用广度优先搜索算法,从前缀树的根节点“由上而下”,找到失败弧的目标节点。
queue = deque()
for token, node in self.root.next.items():
node.fail = self.root
queue.append(node)
while queue:
current_node = queue.popleft()
for token, node in current_node.next.items():
fail = current_node.fail
if token in fail.next:
fail = fail.next[token]
else:
fail = fail.fail
while token not in fail.next:
fail = fail.fail
if fail.token == -1: # root
break
if token in fail.next:
fail = fail.next[token]
node.fail = fail
在某个节点完成失败弧构建之后,立刻构建输出弧,同时更新output_score。
# fill the output arc
output = node.fail
while not output.is_end:
output = output.fail
if output.token == -1: # root
output = None
break
node.output = output
node.output_score += 0 if output is None else output.output_score
queue.append(node)
因为广度搜索从上而下,所以output_core累积了所有输出弧相连的输出节点的分数。
图的搜索
在状态机上搜索一步,需要当前状态和转移条件,这里的转移条件就是下一个token。
def forward_one_step(self, state: ContextState,
token: int) -> Tuple[float, ContextState]:
"""Search the graph with given state and token.
Args:
state:
The given token containing trie node to start.
token:
The given token.
Returns:
Return a tuple of score and next state.
"""
# token matched
if token in state.next:
node = state.next[token]
score = node.token_score
else:
# token not matched
# We will trace along the fail arc until it matches the token or reaching
# root of the graph.
node = state.fail
while token not in node.next:
node = node.fail
if node.token == -1: # root
break
if token in node.next:
node = node.next[token]
# The score of the fail path
score = node.node_score - state.node_score
assert node is not None
return (score + node.output_score, node)
在失败弧上回退时,要减去部分增强分数,见score = node.node_score - state.node_score 。
最后返回这一步的增强得分和下一个状态节点。
在CTC prefix beam search中应用
CTC prefix beam search在解码过程中,每个时刻,规整字符串会在上个时刻的字符串(prefix)上增加一个字符或者保持不变,这时候ContextGraph 会调用一次forward_one_step(),或者不调用。
def total_score(self):
return self.score() + self.context_score
def copy_context(self, prefix_score):
self.context_score = prefix_score.context_score
self.context_state = prefix_score.context_state
def update_context(self, context_graph, prefix_score, word_id):
self.copy_context(prefix_score)
(score, context_state) = context_graph.forward_one_step(
prefix_score.context_state, word_id)
self.context_score += score
self.context_state = context_state
prefix_score是服务CTC prefix beam search算法的数据结构,用来保存某个时刻规整字符串、各种得分和操作对象。
forward_one_step() 的输入参数就是prefix的状态prefix_score.context_state和下一个可能的字符word_id。
self.score()是CTC得分(log后验概率),self.context_score 是热词累积增强得分。